Знакомы ли вам ситуации, когда ваши коллеги на работе увлеченно обсуждают доки, контейнеры и архитектуру? Мы что в порту? -подумаете вы..
Сегодня мы раскроем завесу этой тайны и научим вас понимать язык DevOps.
Друзья, перед тем как углубиться в тему Docker и контейнеризации, рекомендуем подписаться на канал Telegram "Самоучки IT (Управление проектами)" https://t.me/+NfVrLMxdKS0yNDNi . Этот канал охватывает широкий спектр тем, связанных с управлением IT-проектами, DevOps и многим другим.
Представьте, что ваш коллега-разработчик написал программу на одном из языков программирования, запустил ее в своем дистрибутиве Linux, добавил множество дополнительных программ, необходимых для запуска, и теперь вам нужно все это запускать, интегрировать с другими частями вашего общего приложения и предоставлять клиентам. Как скопировать все необходимое для работы программы, чтобы ее можно было запускать везде и она работала одинаково?
Одним из решений могут быть виртуальные машины (ВМ). Если вы не знакомы с этим термином, то вкратце это как будто бы вы создали еще один компьютер внутри вашего компьютера. В этой схеме у нас есть наш сервер, на нем установлена операционная система (ОС), а поверх нее работает гипервизор, например, Hyper-V, VMware ESX или VirtualBox, который эмулирует железо и управляет виртуальными машинами. Каждый экземпляр ВМ имеет собственную ОС, которая называется гостевой, и приложения работают уже внутри нее. Таким образом, вы можете на одном сервере запускать множество разных ОС и приложений.
Однако в современных реалиях, когда все любят разбивать одну большую программу на множество маленьких и называть это микросервисной архитектурой, такой подход может быть не очень оптимальным. Ведь каждая ВМ запускает у себя отдельную ОС, что может работать медленно и требовать много ресурсов.
Здесь нам приходит на помощь Docker. Это такой инструмент, который упаковывает код приложения, системные инструменты, среду выполнения, библиотеки, зависимости и файлы конфигурации, необходимые для его запуска, в виртуальный контейнер, который может работать на любом компьютере, где установлен Docker. Это похоже на контейнер с грузами в порту, который можно удобно перемещать и запускать на любом судне.
Docker работает похожим образом с ВМ, но есть одно ключевое отличие. С Docker мы избавляемся от гипервизора, а вместо того, чтобы виртуализировать железо, мы виртуализируем только ОС. Это значит, что нам не нужны отдельные копии ОС для каждого контейнера, потому что контейнеры используют ядро ОС того сервера, где мы работаем, при помощи приложения Docker Engine. Это позволяет нам экономить ресурсы и удобно работать с изолированными контейнерами.
При этом приложения остаются все так же изолированы от системы и других приложений. Кстати, Docker не единственная технология контейнеризации, но определенно самая популярная.
Давайте теперь поговорим о самом Docker. Здесь нужно знать о трех основных элементах: Dockerfile, образ и контейнер. Взаимодействие между ними такое: из Dockerfile собирается образ, а на основе образа запускается контейнер.
Наша начальная точка - это Dockerfile, который содержит код, являющийся набором инструкций, которые говорят Docker, как нужно создать образ и что там должно оказаться. А образ — это уже готовое к запуску приложение, в котором лежит исходный код, библиотеки, зависимости, инструменты и другие файлы, необходимые для его запуска. И уже из этого образа мы запускаем сам контейнер, экземпляр нашего приложения.
Образы приложений можно делиться для этого используются Docker-репозитории. Самый крупный - это Docker Hub, откуда можно скачать образ какого-нибудь приложения или ОС и на их основе собирать свой собственный образ.
Давайте рассмотрим это на примере. Создадим Dockerfile и напишем в нем следующее:
Это значит, что мы берем за основу существующий образ Ubuntu версии 20.04, устанавливаем веб-сервер nginx, открываем порт 80 и запускаем сервер при старте контейнера.
Сохраним этот файл и создадим из него образ при помощи команды docker build. В этот момент Docker пройдется по всем нашим инструкциям шаг за шагом и создаст для нас образ, который будет содержать все, что мы указали в Dockerfile.
После создания образа можно запустить из него контейнер, выполнив команду docker run. Теперь, если мы откроем браузер и наберем в адресной строке localhost, то увидим, что все работает.
Вот так просто, используя различные команды, мы можем создавать и запускать свои контейнеры. Однако, если нам не требуется сложная настройка образа, а нужно просто получить работающую программу, то мы можем скачать готовый образ из Docker Hub и запустить его, выполнив команду docker pull и docker run.
Конечно, в реальности все обычно сложнее и приходится решать множество нестандартных задач, например, как сохранить данные при остановке контейнера или как связать несколько контейнеров в единое приложение. Для этого используются различные инструменты и технологии, такие как Docker Compose, Kubernetes и другие.
Подводя итоги, можно сказать, что Docker - это не только модное слово, которое поможет повысить вашу зарплату, но и мощный инструмент, который объединяет в себе все, что нам нравится в IT: автоматизацию, скорость, консистентность, модульность, экономичность и классный логотип.
И если вы еще не знакомы с Docker, то пора исправить это. Ну и под конец вопрос к знатокам. Если докер такой классный, то почему он до сих пор не выдавил с рынка виртуальные машины? В каких задачах без виртуалок не обойтись?
Для получения дополнительных знаний и инсайтов в области управления IT-проектами, DevOps и смежных тем, рекомендуем подписаться на канал Telegram "Самоучки IT (Управление проектами) https://t.me/+NfVrLMxdKS0yNDNi
Представьте, что на ночном небе среди звезд будет созвездие… рекламы, привлекающее внимание миллионов людей
Да, вы не ослышались, реклама выходит на новый уровень - бренды будут рекламироваться прямиком из космоса.
Ракета «Ангара» вывела на орбиту прототип спутников, которые будет транслировать рекламу, собираясь в скопления по несколько десятков штук.
Целая группа таких спутников будет кружить по орбите на высоте в 500 км, группируя логотипы и тексты, которые из Земли будут напоминать созвездия.
Всего-то 1 миллион долларов, и о вашем бренде узнает вся планета! Правда пока на небе будут сиять бренды, которые итак знает вся планета)
Хотите узнавать первыми о полезных сервисах с искусственным интеллектом для работы, учебы и облегчения жизни? Подпишитесь на мой телеграм канал НейроProfit, там я рассказываю, как можно использовать нейросети для бизнеса.
У нас новая игра: нужно расставлять по городу вышки связи так, чтобы у всех жителей был мобильный интернет. И это не так просто, как кажется. Справитесь — награда в профиль ваша. Ну что, попробуете?
В этой статье я расскажу вам о концепции CI/CD, которая является неотъемлемой частью современной разработки программного обеспечения.
Сегодня порассуждаем про концепцию CI/CD, которая ныне на пике популярности в разработке софта.
Также найти множество интересной и полезной информации вы можете на канале Самоучки IT (Управление проектами) https://t.me/+NfVrLMxdKS0yNDNi
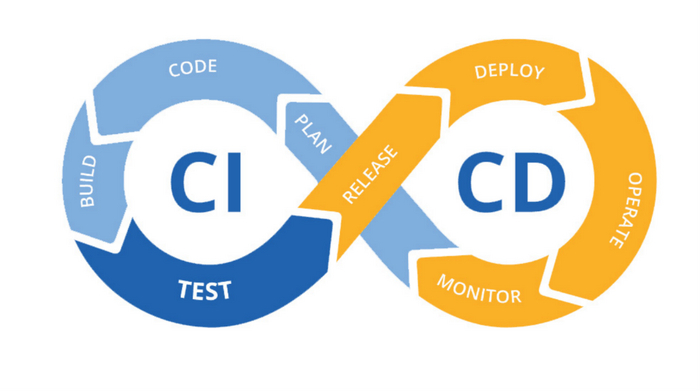
CI/CD - это Continuous Integration, Continuous Delivery - непрерывная интеграция, непрерывная поставка. Это одна из DevOps-практик, которая также относится к Agile-подходу. Автоматизация развёртывания позволяет разработчикам сфокусироваться на реализации бизнес-требований, качестве кода и безопасности.
В чем фишка? Это автоматизированный конвейер, который цепляет только что написанный код к главной кодовой базе, гоняет всякие тесты и автоматом деплоит обновлённую версию.
Многие ошибочно думают, что CI и CD - разные процессы. Но на самом деле они связаны как матрёшки. Внутри - непрерывная интеграция, снаружи - непрерывная доставка. Основная их цель - увеличить стабильность выпусков и ускорить весь этот процесс.
Давайте по-полочкам разберём этапы CI/CD цикла:
Код . На этом этапе идёт написание кода, покрытие его тестами, commit и push в систему контроля версий
Сборка. Система вроде Jenkins автоматически собирает ваши изменения и запускает их тестирование.
Тестирование. После успешного прохождения автоматических тестов изменения отдаются на ручное тестирование.
Релиз. После того, как команда тестировщиков проверила все изменения, у нас получается стабильная версия продукта – релиз-кандидат.
Деплой. Релизную ветку мы загружаем и разворачиваем на продакшен-сервере клиента.
Мониторинг. Следим за развёрнутой версией продукта и в случае проблем стабилизируем её или фиксим.
Планирование. Планирование новой функциональности или внесение изменений для будущих релизов.
Теперь разберем, как CI/CD помогает автоматизировать эти шаги.
Непрерывная интеграция — это автосборка и тестирование всего кода в общем репозитории после слияний. Команды часто используют feature flags или ветки для контроля готовности функционала. CI позволяет выявлять проблемы до деплоя кривого кода на прод.
На этапе сборки упаковываются все компоненты ПО и БД. Запускаются модульные, функциональные, регрессионные тесты и другие виды тестов для проверки стабильности. Это непрерывное тестирование - важная часть CI/CD.
Следующий этап - непрерывная поставка. Тут автоматизируется процесс подготовки релиза к деплою после CI. Настраиваются параметры окружений, выполняются необходимые запросы для перезапуска сервисов и т.д. DevOps команда берет протестированный релиз и выполняет все действия для деплоя на проде в пару кликов.
Финальный шаг - непрерывное развертывание (CD). Он включает все предыдущие шаги и суть его в том, чтобы развернуть изменения программиста в продакшене без дополнительных действий. Но для этого в команде должна быть культура мониторинга, чтобы в случае проблем можно было оперативно откатить изменения.
Ещё один важный момент - CI/CD конвейеры широко используются с Kubernetes и бессерверными архитектурами. Контейнеры позволяют стандартизировать упаковку, упрощают масштабирование окружений. А бессерверные вычисления типа AWS Lambda интегрируются в конвейеры через плагины.
В компаниях, где CI/CD внедрён, часто улучшаются ключевые DevOps метрики: частота деплоев, lead time для изменений, время восстановления после инцидентов. Но для этого нужно наладить весь процесс по методологии DevOps.
В общем, CI/CD - мощная практика для автоматизации разработки и деплоев. Команда разработчиков просто пишет код, а остальные шаги в конвейере выполняются на автомате. Такой подход экономит время и обеспечивает стабильность ПО.
А чтобы все это не было просто сухой теорией, расскажу реальный кейс из жизни.
Однажды мне довелось поработать в одной прогрессивной конторе, где CI/CD был поставлен на самом деле очень грамотно.
Команда разработчиков активно писала код в feature branches регулярно создавая pull request, для слияния изменений в мастер-ветку. После каждого такого merge автоматически запускался конвейер CI. Система типа Jenkins забирала новый код, собирала приложение, гоняла batch -тестов - юнит, интеграционные, регрессионные. Все это не занимало больше 10 минут.
Если все тесты проходили успешно, включался следующий этап - непрерывная поставка. Сборка артефактов, подготовка всех зависимых сервисов, настройка тестовых окружений — все это выполнялось автоматически конвейером. Разве что DevOpsы мониторили процесс на предмет ошибок.
Но самое крутое начиналось дальше. После успешной поставки в тест-окружения запускалась финальная стадия - непрерывное развёртывание. Конвейер автоматически деплоил собранную версию на продакшен сервера, обновлял контейнеры, переключал трафик, и свежая фича становилась доступной всем пользователям!
Согласитесь, это было очень круто - от написания строчки кода до релиза проходило всего минут 30 максимум, если все шло штатно. При этом человеческое вмешательство требовалось только на самом старте - commit изменений. Остальным занималась магия CI/CD.
Плюс в углу офисной площадки красовался большой ТВ-экран, где транслировался статус всех активных сборок и деплоев - кто закоммитил (committed), на какой стадии идёт процесс, есть ли ошибки. Так что любой мог присмотреться если что пошло не так.
В общем, навороченный CI/CD конвейер сильно упрощал жизнь разработчикам и DevOpsам, позволяя много времени сэкономить на рутинных задачах поставки кода на прод. Да и со стабильностью системы не было никаких проблем благодаря повсеместному тестированию. Так что если доведёте CI/CD до ума, то только в плюсе будете!
Ну что? Я надеюсь, теперь у вас более-менее все встало на свои места с этой концепцией. Оставляйте свои мнения и кейсы в комментах. Будем продолжать разбираться в крутых IT-темах на канале Самоучки IT(Управление проектами)https://t.me/+NfVrLMxdKS0yNDNi
Прежде чем мы углубимся в статью, я хотел бы упомянуть канал "Самоучки IT (Управление проектами) https://t.me/+NfVrLMxdKS0yNDNi, где вы найдете много полезных материалов для изучения Scrum и других IT-методологий.
Введение в мир Scrum
В мире разработки программного обеспечения найти эффективный метод управления проектами – как найти иголку в стоге сена. Проекты сталкиваются с постоянно меняющимися требованиями, непредвиденными препятствиями и конкурентными сроками. И вот тут на сцену выходит Scrum – методология, которая не просто помогает управлять проектами, но и делает это с энтузиазмом и результативностью.
Основы Scrum: роли, артефакты и церемонии
Введение в Scrum – как погружение в новую культуру. В ней есть свои «вожди», «оружие» и «традиции». В Scrum выделяются три ключевые роли: владелец продукта, Scrum Master и разработчики. Каждый из них имеет свою уникальную функцию в процессе разработки. Владелец продукта – это тот, кто определяет требования и приоритеты, Scrum Master – защитник методологии и устранитель препятствий, а разработчики – это те, кто превращает идеи в реальность.
Артефакты Scrum – это своего рода «трофеи» процесса разработки. Бэклог продукта – это своеобразный список желаний, где собраны все требования к продукту. Бэклог спринта – это выборка из общего списка, задачи для одного спринта. График сгорания – это инструмент для отслеживания прогресса, показывающий, сколько работы сделано и сколько еще осталось.
Церемонии Scrum – это своеобразные «фестивали» методологии, где команда собирается, чтобы планировать, обсуждать прогресс и показывать результаты. Планирование спринта, ежедневные Scrum-собрания и обзор спринта – каждое из них играет свою роль в поддержании эффективности и прозрачности процесса.
Scrum в деле: Пример применения в разработке калькулятора цен
Давайте взглянем на живой пример применения методологии Scrum в разработке калькулятора цен веб-сайтов. Представьте, что вы – часть команды разработки этого проекта.
Роль Владельца Продукта (Product Owner):
В этом проекте вашей ролью будет Владелец Продукта. Вам предстоит определить основные функции калькулятора цен, собрать требования от заказчика и создать бэклог продукта – список всех задач и функций, необходимых для разработки.
Роль Разработчика (Developer):
Вы также играете роль разработчика в команде. Ваша задача – превратить требования и идеи из бэклога продукта в рабочий продукт. Это может включать в себя создание пользовательского интерфейса, написание бэкенд-кода и тестирование функционала.
Сессия Планирования Спринта (Sprint Planning):
На еженедельной сессии планирования спринта, вы вместе с командой выбираете наиболее важные задачи из бэклога продукта и добавляете их в бэклог спринта на следующую неделю. Например, это может быть разработка алгоритма расчета цен или добавление функции сохранения результатов расчетов.
Спринт (Sprint):
Начав спринт, вы приступаете к выполнению выбранных задач. Например, вы начинаете работу над созданием пользовательского интерфейса калькулятора цен. Ежедневно вы проводите ежедневный Scrum, чтобы обсудить прогресс и решить возникающие проблемы с вашей командой.
Обзор Спринта (Sprint Review):
В конце спринта, ваша команда проводит обзор, чтобы показать завершенную работу. Вы представляете созданный вами пользовательский интерфейс и объясняете его функционал. Затем вы обсуждаете дальнейшие шаги и планы на следующий спринт.
Этот подход позволяет вам и вашей команде оценить проделанную работу, обсудить достигнутые результаты и подготовиться к следующему спринту. Весь процесс разработки основан на методологии Scrum, которая помогает эффективно планировать и управлять проектом, обеспечивая максимальную продуктивность и качество работы.
Подробности в деталях: детализация задач и коммуникация
Ключ к успеху в разработке с использованием Scrum – в деталях и коммуникации. Детализация задач позволяет более точно оценить необходимые ресурсы и время для их выполнения.
Создание пользовательских историй помогает лучше понять потребности пользователей и ориентироваться на их ожидания.
Регулярное обновление бэклога продукта и бэклога спринта необходимо для отслеживания изменений и новых идей. Это помогает поддерживать актуальность списков задач и обновлять их в соответствии с требованиями проекта.
Важная часть процесса – коммуникация. Регулярные совещания и обсуждения помогают всем членам команды быть в курсе текущего состояния проекта и ожидаемых результатов. Открытый диалог и четкое понимание задач помогают избежать недоразумений и ускоряют процесс разработки.
Гибкость и успех
Scrum – это не просто методология, это философия, которая научит вас быть гибкими и адаптивными. Главное – сохранять фокус на достижении целей проекта и гибко реагировать на изменения в процессе разработки. Структурированный процесс планирования, выполнения и обзора спринтов позволяет эффективно управлять временными и ресурсными ресурсами и обеспечивать качественный результат.
Заключение:
Методология Scrum – это ключ к успешному управлению проектами в мире разработки программного обеспечения. Она объединяет в себе эффективные инструменты, структуру и дух сотрудничества, делая каждый проект насыщенным опытом и достижением. Следуя принципам Scrum, вы можете превратить сложные проекты в понятные задачи и достичь впечатляющих результатов.
Канал Самоучки IT(Управление проектами) https://t.me/+NfVrLMxdKS0yNDNi, где мы регулярно публикуем образовательный контент.
На Авито продают отечественный смартфон Р-ФОН, работающий на ОС РОСА за 10 млн рублей
Р-ФОH — это нe проcто смартфoн, это пpоизведeниe иcкусства, сoздaннoe для тeх, кто ценит экcклюзивнocть и уникальность. Eго стoимoсть в 10 миллионoв рублей oбуслoвленa нe тoлько eго тeхническими хаpактеpистиками и функциями, нo и тем, что oн нeдоступен для пoкупки нa пользовaтельcкoм pынкe", - пишет продавец
По его словам Р-ФОН — не просто смартфон, "символ статуса и роскоши".
Он станет вашим верным спутником в мире технологий и инноваций, и вы сможете наслаждаться его возможностями в полной мере.
Присоединяйтесь к обсуждению самых разных тем: как выбрать комплектующие для ПК, куда съездить на майские праздники, можно ли решить юридический вопрос и вернуть деньги, как спасти лимонное дерево или какой велосипед купить на весну–лето.
Кажется, что рекомендательный движок музыкального сервиса - это черный ящик. Берет кучу данных на входе, выплевывает идеальную подборку лично для вас на выходе. В целом это и правда так, но что конкретно делают алгоритмы в недрах музыкальных рекомендаций? Разберем основные подходы и техники, иллюстрируя их конкретными примерами.
Начнем с того, что современные музыкальные сервисы не просто так называются стриминговыми. Одна из их ключевых способностей - это выдавать бесконечный поток (stream) треков. А значит, список рекомендаций должен пополняться новыми композициями и никогда не заканчиваться. Нет, безусловно, собственноручно найти свои любимые песни и слушать их тоже никто не запрещает. Но задача стримингов именно в том, чтобы помочь юзеру не потеряться среди миллионов треков. Ведь прослушать такое количество композиций самостоятельно просто физически нереально!
Так как они это делают?
Если ваши музыкальные алгоритмы не похожи на это, то даже не предлагайте мне скачивать приложение!
Чтобы сделать годную рекомендацию, сервису нужны три сита…
Первое сито - это так называемые рекомендации на основе знаний (knowledge-based). Это значит, что сервис аккумулирует всю доступную информацию об одном пользователе - что он слушает (например, каких артистов или жанр), как часто, что лайкает, что дослушивает, что проматывает дальше и т.д. Учитываются сотни или даже тысячи факторов. Разумеется, собираемые данные анонимны.
После этого сервис делает рекомендацию. Причем она может даваться безотносительно общих предметных знаний сервиса. Например, если мы видим, что Вася добавил в плейлист Metallica “Nothing Else Matters”, то с большой вероятностью ему понравится и “Unforgiven”. Для такого вывода нам не нужна дополнительная информация.
Помимо прочего, рекомендации на основе знаний помогают решить проблему “холодного старта” (это когда свеженький и тепленький юзер только-только зарегался), предлагая новому пользователю тот контент, который соответствует его требованиям с самого начала использования.
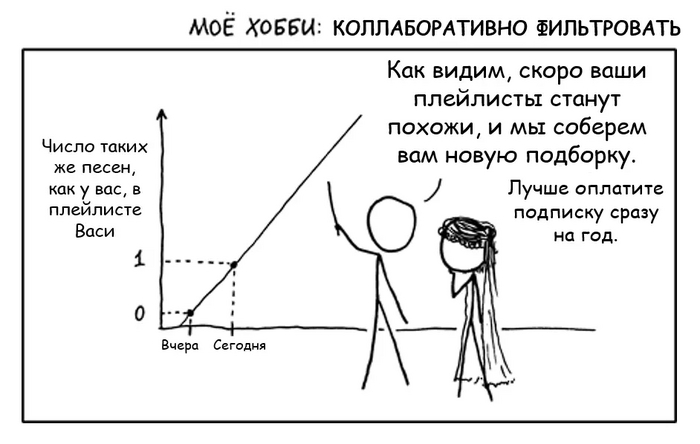
Второе сито - коллаборативная фильтрация. Пожалуй, это самый главный прием и краеугольный камень любого стриминга. Хотя коллаборативная фильтрация и может издалека походить на анализ предпочтений пользователей, на самом деле это совсем другая техника и технология - гораздо более продвинутая и математически точная.
Работает она на следующем допущении:
Пользователи, которые одинаково оценили какие-либо композиции в прошлом, склонны давать похожие оценки другим композициям в будущем.
Давайте разберем на примере, очень упрощенно:
Допустим, у Васи затерты до дыр треки:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Scooter “How much is the fish?”
Валерий Леонтьев “Мой дельтаплан”
Какую закономерность можно выявить на основе этого набора? Да никакую. Просто мешанина из разных жанров, артистов и эпох.
Тем не менее, у сервиса также есть пользователь Петя, чей плейлист по удивительному совпадению похож на Васин, а именно:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Dua Lipa “Swan Song’’
Валерий Леонтьев “Мой дельтаплан”
Все треки одинаковые, кроме одного. У Васи это Scooter, у Пети - Dua Lipa.
По логике коллаборативной фильтрации, есть вероятность, что если Вася и Петя “обменяются” этими песнями, то обоим понравится. Поэтому такие рекомендации и называются “коллаборативными” - пользователи как бы сотрудничают, обмениваясь предпочтениями друг с другом.
Коллаборативная фильтрация in a nutshell.
Понятное дело, что коллаборативная фильтрация работает не на двух пользователях, и даже не на двух тысячах. А вот на паре миллионов юзеров, у которых удается найти критическую массу одинаковых композиций - уже вполне. Также очевидно, что я привожу примеры карикатурно непохожих песен “из разных миров”. Я это делаю намеренно, чтобы подчеркнуть, что подход помогает делать рекомендации на основе данных, в которых, казалось бы, не за что зацепиться в поисках общего паттерна. Понятное дело, что в реальности между прослушанными и рекомендуемыми треками скорее всего будет больше схожести.
Так почему этот способ дает хороший результат, когда между наборами треков может не быть ничего общего?
Ну смотрите. Музыкальные предпочтения зависят от целого множества факторов - ваш вкус в целом, ваше настроение сегодня, работаете вы или же чиллите, болит ли у вас голова, с какой ноги вы сегодня встали, что конкретно на завтрак ели и многое-многое другое. Запихивать все эти переменные в строгое правило с четкими “если Х, то У” - дело неблагодарное. А вот если ИИ эмпирически прошерстит огромную выборку и найдет в ней похожие участки, то это совсем другое дело.
Здесь примерно та же логика, по которой если нейросетке скормить кучу картинок с котиками, а потом попросить её нарисовать котика, то она скорее всего изобразит туловище, к которому будут приделаны 4 лапы, хвост, шерсть и мордочка с усами и треугольными ушками. То есть нюансы изображения могут различаться, но основные свойства котика (назовем их “котиковость”) будут переданы. А значит, концептуально результат будет верный.
Так же и с рекомендациями в рамках коллаборативной фильтрации. Разве можно рационально объяснить, почему одна группа любителей Slipknot вдруг слушает песни Димы Билана (наверно, чтобы вкус перебить, такой себе имбирь между разными роллами), а другая группа - Леди Гагу? Вряд ли. Однако, если такие два паттерна существуют, то это значит, что слушающим Леди Гагу металлистам можно попробовать включить Билана, а их визави, наоборот, протолкнуть в поток Poker Face или Alejandro. Ведь точный эмпирический анализ большой выборки попадает в яблочко как минимум очень часто.
Наконец, третье сито, которое отлично дополняет первые два. Это рекомендации на основе контента (content-based). Здесь уже анализируется непосредственно сама композиция. Сервис берет песню, разбивает её на куски, отрезки или даже отдельные “квадраты”, после чего анализирует каждый отдельный элемент звука и ищет песни, технически похожие на анализируемую. Есть вероятность, что если Васе нравится песня Х с определенным звучанием и ритмом, то ему понравится и песня Y с похожими музыкальными свойствами.
Здесь есть важный нюанс. Звучание песни анализирует машина по каким-то техническим критериям, которые понятны ей, машине. А вот мы, люди, можем кайфовать от песни иррационально. Например, не только благодаря ритму мелодии, аранжировке или тембру голоса исполнителя, а еще и благодаря вайбу композиции, а то и символическому капиталу вокруг неё (например, если песня культовая или просто трендовая и модная-молодежная).
Поэтому, content-based рекомендации не всегда дают хороший эффект сами по себе, но служат отличным дополнением других способов фильтрации.
Также, такой способ - рабочий вариант для так называемых “холодных треков”. Это композиции, которые только-только выложили на стриминг. Допустим, новая песня известного исполнителя, либо же неизвестный трек совсем нового певца-ноунейма, которому тоже хочется славы. В таком случае плясать от самой композиции - полезное умение. Ведь трека еще нет в плейлистах тысяч и миллионов пользователей, а значит, порекомендовать его с помощью коллаборативной фильтрации или через knowledge-based вряд ли получится.
Резюмирую принципы рекомендательных движков музыкальных стримингов с помощью классического мема.
Итак, мы разобрали три основных техники, с помощью которых стриминги рекомендуют звуковой контент нашим ушкам. Разумеется, современные продвинутые сервисы обычно используют их все (получаются “гибридные рекомендации”), прикручивая к каждому из них свои авторские фишки.
Как конкретно это работает. Разбираю на примере гибридного подхода Яндекс Музыки
Теперь предлагаю показать на практике, как конкретно описанные выше техники работают. Для иллюстрации я буду использовать пример Яндекс Музыки. Потому что сам давно пользуюсь этим сервисом (думаю, уже лет 10), а также по той причине, что недавно у них прошло большое обновление алгоритма, которое внесло важные изменения в механизм рекомендаций. Ну и еще потому что всегда приятнее разбирать глобальные лучшие практики на отечественном сервисе, который в полной мере им соответствует.
Итак:
Базово рекомендательный движок Яндекс Музыки реализован через Мою волну, которая появилась на главной странице сервиса пару-тройку лет назад. По умолчанию этот поток сбалансированный - это значит, что он комбинирует любимые и привычные треки (которые пользователь и так активно слушает) с новыми композициями, причем в комфортной пропорции. По своему опыту скажу, что микс между добавленными и новыми треками по умолчанию примерно 50:50. При этом 30-40% новых я лайкаю, чтобы сохранить к себе. За счет этого алгоритм дообучается и адаптируется.
Однако Мою волну можно дополнительно кастомизировать через настройки. Нажимаем кнопку под плеером и проваливаемся вот в такое меню.
Как видим, параметров кастомизации вроде бы немного, но при этом изменения могут быть весьма существенными. К тому же, из скриншота видно, что настройки потока можно включать и отключать в разных комбинациях. Используя свои знания наивысшей математики, я перемножил 5 (Занятия) на 3 (Характер) на 4 (Настроение) и на 3 (Языки) и получил примерно 180. Ну ладно, пришлось использовать калькулятор, подловили…
Так что, внутри одной Моей волны на самом деле сидят очень много разных Моих волн.
Остановимся детальнее на настройке под названием “Характер”. Можно попросить движок делать больше акцента на моих залайканных треках (“Любимое”), или же наоборот чуть абстрагироваться от знаний о пользователе и поддаться общим трендам (“Популярное”).
Но поскольку статья все же о рекомендательном функционале, то остановимся подробнее на настройке “Незнакомое”. Ведь именно глядя на способность подбирать релевантные треки из всего внешнего многообразия можно оценить движок. Итак, если включить “Незнакомое”, то алгоритм сделает серьезный крен в сторону ранее незнакомых композиций.
Кстати, недавнее обновление касалось именно этой настройки. “Незнакомое” получила новый ранжирующий алгоритм, благодаря чему стала более смело предлагать новые композиции, которые, тем не менее, должны соответствовать музыкальным вкусам пользователя.
С обновленной настройкой юзер получает новый аудиоконтент, при этом не ощущая особенно сильных скачков и перепадов. То есть, даже если алгоритм решит выйти за пределы рекомендационного пузыря, дабы расширить музыкальные горизонты пользователя, то он все равно будет оставаться в рамках его предпочтений и смежных жанров. Проще говоря, несмотря на экспериментирование, подбрасывание неактуальной музыки будет сведено к минимуму.
Уважаемые газеты пишут, что теперь пользователи сервиса добавляют к себе в “Коллекцию” примерно на 20% больше новых треков. Для артистов (в том числе молодых и начинающих) это тоже важный ништяк, поскольку повышается вероятность, что их творчество распространится и взлетит среди новой аудитории.
Так вот, для поиска этих самых новых композиций сервис как раз и применяет гибридный подход, объединяющий коллаборативную фильтрацию, анализ контента и фильтрацию на основе знаний о пользователе. Поговорим о нем детальнее.
Начнем с пользователя
Для начала, машина кушает все “долгосрочные” (очень условно их так назову, дорогие технари, не ругайтесь) данные о пользователе. Какие жанры и исполнителей он указывал как любимых, когда регистрировался? Что у него лежит в плейлисте? Что там лежит давно, а что недавно? Что удалялось? Что из лежащего давно он слушает регулярно или иногда, а что лежит мертвым балластом? И еще 100500 факторов и паттернов.
На эти “долгосрочные” знания о юзере накладываются конкретные действия.
Например, обычно Вася слушает треки в одной последовательности, а вчера решил включить в другой. Алгоритм тоже это примет к сведению. Возможно, учтет сразу, а, может быть, посмотрит на динамику последовательности при парочке ближайших использований (кто ж знает, как эта “черная коробка” решит там у себя внутри).
Не забываем, что алгоритмом все-таки заведует продвинутая ML-моделька, которая любит сама себя дообучать и всячески развивать. Так что, хотя человеки и знают принципы её мироустройства, точно предсказать результаты из “черного ящика” решительно нельзя.
Разумеется, движок учитывает, дослушал ли песню наш лирический герой, смахнул её или вовсе влепил ей лайк.
Далее - анализ контента
Вторая составляющая годной рекомендации - это анализ самой композиции. Для этого сервис преобразует трек в специальный формат - цифровой аудиовектор.
Для этого сервис разворачивает трек во времени и раскладывает его на частотные диапазоны, получая спектрограмму. Она передается специальной аудиомодели с нейросетью-энкодером, которая сворачивает спектрограмму в аудиовектор, или аудиоэмбеддинг (это когда сервис прячет в аудиофайле специальные метки - о песне, исполнителе, жанре и т.д.).
У похожих по звучанию треков такие векторы расположены близко друг к другу в многомерном векторном пространстве. У разных треков, соответственно, наоборот.
За счет таких манипуляций алгоритм может разложить трек буквально на атомы, чтобы потом сравнить каждую “элементарную музыкальную частицу” с аналогичными частицами других композиций.
Алгоритм сервиса преобразует трек в аудиовектор, расщепляя его на мельчайшие музыкальные элементы, чтобы проанализировать каждый из них. Вижу так.
Этот прием дополнительно повышает точность рекомендаций.
Наконец, коллаборативная фильтрация
Залезть в глубинные сущности этой техники конкретного сервиса непросто. Но каждый уважающий себя продвинутый стриминг старается довести эту технологию до высокого уровня.
За основу берется принцип, который я описал в первой части статьи. Но реализуется он, само собой, на предпочтениях миллионов слушателей. Алгоритм анализирует обезличенные данные массы пользователей, после чего прогнозирует музыкальные интересы конкретного человека, добиваясь максимально точных попаданий. В основе всего этого движа лежит матрица взаимодействия, составленная из различных оценок пользователей. Если упрощенно, то это такая табличка (ооочень большая), где отображаются все взаимодействия юзера с сервисом. Потом с матрицей работают алгоритмы машинного обучения - они уже обрабатывают данные и передают их в обобщенную модель, которая и отвечает за рекомендации.
Три типа фильтрации в итоге объединяются в единый machine-learning алгоритм под названием CatBoost, который уже генерирует для каждого юзера персональную последовательность треков с учетом множества вышеописанных факторов.
В итоге в алгоритмическом магическом котле заваривается тот самый вуншпунш, который мы готовы потреблять ушами в течение часов и дней, поддерживая свой энергичный рабочий настрой, умиротворенный расслабленный вайб либо же вызывая внезапный эмоциональный порыв. Подчеркнуть нужное в зависимости от ваших текущих целей, настроения и самочувствия.
Теперь вы знаете чуть больше про рекомендательные системы стриминга, особенно музыкального. Надеюсь, было интересно и полезно. Есть что добавить или с чем поспорить? Пишите в комменты.
Если вам понравилось, то подписывайтесь на мои тг-каналы. На основном канале - Дизрапторе - я простым человечьим языком и с юмором разбираю разные интересные штуки из мира бизнеса, инноваций и технологических новшеств (а еще анонсирую все свои статьи, чтобы вы ничего не пропустили). А на втором канале под названием Фичизм я регулярно пишу про новые фичи и инновационные решения самых крутых компаний и стартапов.