

Гугл сегодня
Всех причастных с праздником! Пусть наши дети и мужья скорее вернутся домой.
Всех причастных с праздником! Пусть наши дети и мужья скорее вернутся домой.
Предложена Ютуба через 5 минут:


Компания Google уволила 28 сотрудников после их участия в забастовке длительностью восемь часов, которая проходила в офисах корпорации, расположенных в Нью-Йорке и калифорнийском Саннивейле. Работники выступали против сотрудничества Google с израильским правительственным проектом Nimbus.
Как сообщает издание New York Post, ссылаясь на Криса Рэкоу, руководителя отдела глобальной безопасности компании, протестующие объясняли свои действия нежеланием «работать над технологией, которая убивает людей, способствует геноциду, апартеиду или слежке». Часть протестующих забаррикадировались в кабинете генерального директора Google Cloud Томаса Куриана. Работники вели прямую трансляцию своего протеста, на которой также был запечатлен момент задержания пяти человек.
Внутреннее сообщение компании, дошедшее до прессы, свидетельствует, что компания запустила расследование инцидента и решила уволить 28 работников за действия, которые привели к захвату офисных пространств, повреждению имущества и нарушению работы других сотрудников.
«Физическое воспрепятствование работе других сотрудников и лишение их доступа к нашим объектам является явным нарушением нашей политики и абсолютно неприемлемым поведением. <…> На данный момент мы завершили индивидуальные расследования, которые привели к увольнению 28 сотрудников, и будем продолжать расследование и принимать необходимые меры», – говорится в заявлении Google.
Представитель полиции Нью-Йорка сообщил, что всего в протесте участвовало около 50 человек, четверо из них были задержаны за незаконное проникновение в помещения Google.
Выспаться, провести генеральную уборку, посмотреть все новые сериалы и позаниматься спортом. Потом расстроиться, что время прошло зря. Есть альтернатива: сесть за руль и махнуть в путешествие. Как минимум, его вы всегда будете вспоминать с улыбкой. Собрали несколько нестандартных маршрутов.
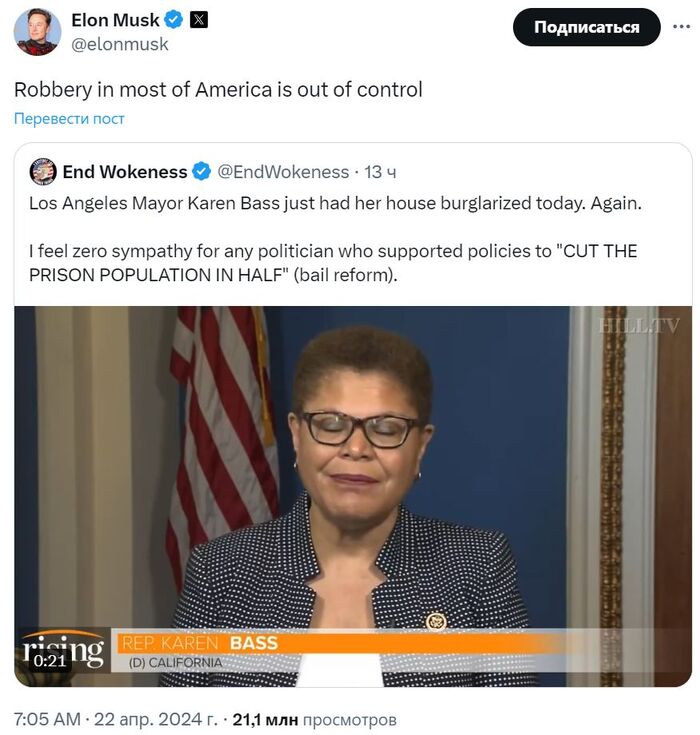
Сегодня мэру Лос-Анджелеса Карен Басс ограбили дом. Снова. Я не испытываю никакой симпатии к любому политику, который поддерживал политику «СОКРАЩЕНИЯ НАСЕЛЕНИЯ ТЮРЬМОВ ПОЛОВИНУ» (реформа залога). [ перевод Google ]
Источник: Маск; X ( twitter )
Google уволил 28 человек из-за сидячих протестов против сделки компании с Израилем
Сотрудники пришли в кабинет СЕО Google Cloud с требованием отказаться от контракта на 1,2 млрд долларов с правительством Израиля. Как итог — протестующих не просто уволили, а ещё и арестовали.
На видео сам протест.

Технологические гиганты OpenAI, Google и Meta* в погоне за онлайн-данными для обучения своих новейших систем искусственного интеллекта готовы на всё: игнорировать корпоративные политики, менять собственные правила и даже обсуждать возможность обхода законов об авторском праве.
Одним из самых вопиющих примеров стали действия исследователей OpenAI в Сан-Франциско. Они разработали инструмент для транскрибирования видео с YouTube, чтобы собрать огромный массив разговорных текстов для развития ИИ. Некоторые сотрудники OpenAI выражали обеспокоенность тем, что такой шаг может нарушать правила YouTube, которые запрещают использовать видео платформы для "независимых" приложений. Однако в итоге команда во главе с президентом компании Грегом Брокманом, который лично участвовал в сборе данных, расшифровала более миллиона часов видео. Полученные тексты были загружены в GPT-4 - одну из самых мощных языковых моделей в мире, лежащую в основе чат-бота ChatGPT.
Эта история наглядно демонстрирует, насколько отчаянной стала гонка за цифровыми данными, необходимыми для прогресса ИИ. Ради заветных терабайтов информации технологические компании, включая OpenAI, Google и Meta*, готовы срезать углы, игнорировать внутренние политики и балансировать на грани закона. Расследование New York Times показало, что эти ИТ-гиганты всерьез обсуждали возможность обхода авторских прав ради пополнения своих баз данных.
В Meta*, которой принадлежат Facebook* и Instagram* , менеджеры, юристы и инженеры всерьез рассматривали вариант покупки издательства Simon & Schuster, чтобы заполучить большой объем книг. Они также обсуждали идею собирать защищенные авторским правом данные по всему интернету, даже если это грозило судебными исками. По их мнению, переговоры о лицензировании с издателями, авторами, музыкантами и новостной индустрией заняли бы слишком много времени.
Google, как и OpenAI, расшифровывал видео с YouTube для получения текстовых данных, потенциально нарушая авторские права создателей контента. Кроме того, в прошлом году компания расширила свои условия использования сервисов. Одной из причин этого изменения, по словам сотрудников отдела конфиденциальности и внутренних документов, стало желание получить возможность анализировать публично доступные файлы Google Docs, отзывы на Google Maps и другие онлайн-материалы для использования в своих ИИ-продуктах.

Эти примеры показывают, что новости, художественные произведения, посты на форумах, статьи из Википедии, компьютерные программы, фотографии, подкасты и фрагменты фильмов стали настоящей "цифровой кровью", питающей бурно развивающуюся индустрию искусственного интеллекта. Создание инновационных систем напрямую зависит от наличия достаточного объема данных для обучения ИИ мгновенной генерации текстов, изображений, звуков и видео, неотличимых от созданных человеком.
Объем данных имеет решающее значение. Ведущие чат-боты обучались на массивах цифровых текстов, включающих до трех триллионов слов - примерно вдвое больше, чем хранится в Бодлианской библиотеке Оксфордского университета, которая собирает рукописи с 1602 года. По словам исследователей ИИ, наиболее ценными являются высококачественные данные, такие как опубликованные книги и статьи, тщательно написанные и отредактированные профессионалами.
Долгие годы интернет с такими сайтами, как Википедия и Reddit, казался неиссякаемым источником данных. Но по мере развития ИИ технологические компании стали искать новые резервуары информации. Google и Meta, имеющие миллиарды пользователей, ежедневно генерирующих поисковые запросы и посты в соцсетях, во многом ограничены законами о конфиденциальности и собственными политиками в плане использования этого контента для обучения ИИ.
Ситуация становится критической. По прогнозам исследовательского института Epoch, уже к 2026 году технологические компании могут исчерпать все качественные данные, доступные в интернете. Гиганты индустрии потребляют информацию быстрее, чем она производится.
"Единственный практичный способ существования этих инструментов - это возможность обучать их на огромных объемах данных без необходимости лицензирования", - заявил Сай Дамл, юрист, представляющий интересы венчурной компании Andreessen Horowitz, в ходе публичной дискуссии об авторском праве. "Необходимый объем данных настолько огромен, что даже коллективное лицензирование не сможет решить проблему".
Технологические компании настолько жаждут новых данных, что некоторые из них разрабатывают "синтетическую" информацию. Речь идет не об органическом контенте, созданном людьми, а о текстах, изображениях и коде, генерируемых самими ИИ-моделями. Иными словами, системы учатся на том, что создают сами.

OpenAI заявила, что каждая ее ИИ-модель "имеет уникальный набор данных, который мы тщательно подбираем, чтобы улучшить их понимание мира и оставаться глобально конкурентоспособными в исследованиях". Google отметила, что ее модели "обучаются на некотором контенте YouTube" в рамках соглашений с авторами, и что компания не использует данные из офисных приложений вне экспериментальной программы. Meta* подчеркнула, что "агрессивно инвестировала" в интеграцию ИИ в свои сервисы и имеет миллиарды публично доступных изображений и видео из Instagram* и Facebook* для обучения своих моделей.
Для создателей контента растущее использование их произведений ИИ-компаниями стало поводом для исков о нарушении авторских прав и лицензировании. The New York Times подала в суд на OpenAI и Microsoft за использование защищенных авторским правом новостных статей без разрешения для обучения чат-ботов. OpenAI и Microsoft заявили, что использование материалов было "добросовестным" и разрешенным законом, поскольку оригинальные тексты были трансформированы для другой цели.
Более 10 000 торговых групп, авторов, компаний и других организаций направили свои комментарии по поводу использования творческих работ ИИ-моделями в Бюро авторских прав США - федеральное агентство, готовящее рекомендации по применению копирайта в эпоху ИИ.
Режиссер, актриса и писательница Джастин Бейтман заявила Бюро, что ИИ-модели используют контент, включая ее книги и фильмы, без разрешения и оплаты. "Это крупнейшая кража в истории Соединенных Штатов, точка", - подчеркнула она в интервью.

В январе 2020 года теоретический физик из Университета Джонса Хопкинса Джаред Каплан опубликовал новаторскую статью об ИИ, которая разожгла аппетит технологических гигантов к онлайн-данным. Его вывод был однозначен: чем больше информации, данных - "цифровой крови" ИИ-систем, будет использовано для обучения большой языковой модели (ключевой технологии чат-ботов), тем лучше будут её результаты. Подобно тому, как студент становится образованнее, прочитав больше книг, ИИ-алгоритмы могут точнее распознавать паттерны в тексте и давать более точные ответы, впитав больше данных.
"Все были поражены тем, что эти закономерности, которые мы называем "законами масштабирования", оказались столь же точными, как и те, что мы наблюдаем в астрономии или физике", - отметил доктор Каплан, опубликовавший статью в соавторстве с девятью исследователями OpenAI (сейчас он работает в ИИ-стартапе Anthropic).
Лозунг "Масштаб решает все" быстро стал боевым кличем для всей индустрии ИИ, ознаменовав начало безудержной гонки за данными, этой "цифровой кровью" для алгоритмов. Исследователи, которые раньше довольствовались относительно скромными публичными базами данных вроде Википедии или Common Crawl (архива из более чем 250 миллиардов веб-страниц, собираемого с 2007 года), осознали, что в новую эпоху этой информации катастрофически мало. Если до статьи Каплана датасеты с 30 000 фотографий с Flickr считались ценным ресурсом, то теперь ИИ-системам требовались терабайты текстов, изображений и другого "топлива" для развития.

Когда в ноябре 2020 года OpenAI представила GPT-3, эта модель была обучена на рекордном на тот момент объеме данных - около 300 миллиардов "токенов" (по сути, слов или частей слов). Впитав эту гору информации, система начала генерировать тексты с пугающей точностью, создавая блог-посты, стихи и даже компьютерные программы.
Гонка за "цифровой кровью" только начиналась. В 2022 году лаборатория DeepMind, принадлежащая Google, провела эксперимент с 400 ИИ-моделями, варьируя объем обучающих данных. Лучшие результаты показали системы, питавшиеся еще большим объемом информации, чем предсказывал Каплан. Модель Chinchilla "выпила" 1.4 триллиона токенов.
Но и этот рекорд вскоре был побит. В прошлом году китайские исследователи представили Skywork - ИИ-модель, обученную на 3.2 триллиона токенов из английских и китайских текстов. А Google анонсировала систему PaLM 2, проглотившую умопомрачительные 3.6 триллиона токенов - настоящее море данных.
Алгоритмы-вампиры вошли во вкус. И теперь уже ничто не могло остановить их ненасытную жажду информации, столь необходимой для развития ИИ...

В мае Сэм Альтман, генеральный директор OpenAI, признал, что запасы ценной информации в интернете скоро иссякнут под натиском ИИ-компаний, одержимых идеей масштаба. "Этот ресурс не бесконечен", - заявил он в своей речи на технологической конференции.
Альтман знал, о чем говорит. В OpenAI исследователи годами собирали данные, очищали их и скармливали ненасытным алгоритмам, превращая в топливо для обучения языковых моделей. Они выкачивали код с GitHub, поглощали гигантские базы шахматных партий, анализировали школьные тесты и домашние задания с сайта Quizlet. Но к концу 2021 года эти источники истощились, рассказали восемь человек, знакомых с ситуацией в компании.
OpenAI отчаянно нуждалась в новой информации для своего ИИ следующего поколения - GPT-4. Сотрудники обсуждали идеи транскрибировать подкасты, аудиокниги и видео с YouTube, создавать данные с нуля с помощью других ИИ-систем и даже покупать стартапы, накопившие большие объемы цифрового контента.
В итоге OpenAI создала инструмент распознавания речи Whisper, чтобы извлекать тексты из YouTube-роликов и подкастов, рассказали шесть человек. Однако правила YouTube запрещают не только использовать видео в "независимых" приложениях, но и получать доступ к контенту платформы "любыми автоматическими средствами (такими как роботы, ботнеты или скраперы)".
Сотрудники OpenAI понимали, что вступают в серую зону закона, но считали, что обучение ИИ на этих видео - это "добросовестное использование". Грег Брокман, президент компании, лично участвовал в сборе роликов с YouTube и скармливал их Whisper, став одним из создателей инструмента.
В прошлом году OpenAI выпустила GPT-4, модель, обученную на более чем миллионе часов видео, которые Whisper извлек с YouTube и превратил в бесценный ресурс для развития ИИ. Команду разработки GPT-4 возглавлял лично Брокман.

Некоторые сотрудники Google знали о практиках OpenAI, но не препятствовали им, так как сам Google использовал транскрипты YouTube-видео для обучения своих ИИ-моделей, рассказали два человека, знакомых с ситуацией. Такой подход мог нарушать авторские права создателей контента. Если бы Google попытался предъявить претензии OpenAI, это могло вызвать общественный резонанс и привести к скандалу вокруг методов самого техногиганта.
Алгоритмы продолжали безнаказанно высасывать данные из YouTube, превращая видео в топливо для развития ИИ, невзирая на правила платформы и вопросы этики. Жажда информации, разожженная гонкой за лидерство в сфере ИИ, оказалась сильнее угрызений совести и страха перед законом.

В прошлом году Google внес изменения в свою политику конфиденциальности для бесплатных потребительских приложений. Согласно новой формулировке, компания использует информацию для улучшения сервисов, разработки новых продуктов, функций и технологий, которые приносят пользу как самим пользователям, так и обществу в целом.
Особое внимание было уделено использованию общедоступной информации для обучения языковых моделей ИИ и создания продуктов вроде Google Translate, чат-бота Bard и облачных ИИ-сервисов. Это дало Google гораздо более широкие возможности для сбора и анализа данных в целях развития искусственного интеллекта.
Однако эти изменения вызвали вопросы у членов команды по конфиденциальности. В августе двое из них обратились к менеджерам, чтобы прояснить, сможет ли Google начать использовать данные из бесплатных потребительских версий Google Docs, Google Sheets и Google Slides. По их словам, они не получили четких ответов.
Мэтт Брайант, представитель Google, заявил, что изменения в политике конфиденциальности были сделаны для ясности и что компания не использует информацию из Google Docs или связанных приложений для обучения языковых моделей "без явного разрешения" пользователей. Он уточнил, что речь идет о добровольной программе, которая позволяет пользователям тестировать экспериментальные функции.
"Мы не начали обучение на дополнительных типах данных на основе этого изменения формулировки", - подчеркнул Брайант.
Тем не менее, обновленная политика конфиденциальности дает Google гораздо больше пространства для маневра в плане использования пользовательских данных для развития ИИ. И хотя компания отрицает, что уже применяет информацию из своих офисных приложений для обучения языковых моделей, сама возможность такого использования вызывает вопросы у экспертов по конфиденциальности.

Ясно одно: в гонке за лидерство в сфере ИИ техногиганты готовы использовать все доступные ресурсы, и данные миллионов пользователей - слишком лакомый кусок, чтобы его игнорировать. Вопрос лишь в том, насколько далеко Google и другие компании готовы зайти в погоне за прогрессом, и сумеют ли они найти баланс между развитием технологий и защитой приватности своих клиентов.

Марк Цукерберг, глава Meta, годами инвестировал в развитие искусственного интеллекта. Однако когда в 2022 году OpenAI выпустила свой чат-бот ChatGPT, Цукерберг внезапно осознал, что его компания отстает в гонке ИИ-вооружений. По словам трех нынешних и бывших сотрудников, он немедленно начал оказывать давление на своих подчиненных, требуя в кратчайшие сроки создать чат-бот, способный превзойти детище OpenAI. Руководители и инженеры получали звонки от босса в любое время дня и ночи.
Но уже к началу прошлого года Meta* столкнулась с той же проблемой, что и ее конкуренты: нехваткой данных для обучения ИИ. Ахмад Аль-Дахле, вице-президент компании по генеративному ИИ, сообщил руководству, что его команда использовала практически все доступные в интернете англоязычные книги, эссе, стихи и новостные статьи для разработки своей модели. Без расширения массива данных Meta* не сможет догнать ChatGPT, подчеркнул он.
В марте и апреле 2023 года лидеры бизнес-подразделений, инженеры и юристы Meta* практически ежедневно собирались, чтобы найти решение проблемы. Одни предлагали платить по 10 долларов за книгу, чтобы получить полные лицензионные права на новые произведения. Другие обсуждали возможность приобретения издательства Simon & Schuster, выпускающего книги таких авторов, как Стивен Кинг.
Но звучали и более радикальные идеи. Сотрудники говорили о том, что уже обобщали книги, эссе и другие произведения из интернета без разрешения правообладателей. Они всерьез рассматривали возможность и дальше "высасывать" защищенный авторским правом контент, даже если это грозило судебными исками. Один из юристов предупредил о "этических" проблемах, связанных с использованием интеллектуальной собственности без ведома и согласия авторов, но его слова были встречены гробовым молчанием.
Цукерберг требовал найти решение любой ценой. "Возможности, которые Марк хочет видеть в нашем продукте, мы сейчас просто не в состоянии обеспечить", - признал один из инженеров.
Несмотря на то, что Meta* управляет гигантскими социальными сетями, у компании не было достаточного объема пользовательских постов, пригодных для обучения ИИ. Многие пользователи Facebook* удаляли свои старые публикации, а сама платформа не располагала к созданию длинных текстов, подобных эссе. К тому же, после скандала 2018 года, связанного с передачей данных пользователей компании Cambridge Analytica, занимавшейся профилированием избирателей, Meta* была вынуждена ввести ограничения на использование информации о своих юзерах.
В недавнем обращении к инвесторам Цукерберг заявил, что миллиарды публично доступных видео и фотографий на Facebook* и Instagram* представляют собой массив данных, превосходящий Common Crawl (базу из сотен миллиардов веб-страниц, используемую для обучения ИИ). Но хватит ли этого, чтобы догнать и обогнать конкурентов?
В своих внутренних обсуждениях топ-менеджеры Meta* признавали, что OpenAI, судя по всему, использовала защищенные авторским правом материалы без разрешения. И хотя некоторые сотрудники поднимали вопросы об этичности такого подхода и справедливой оплате труда авторов, общий вывод был таков: Meta* может последовать этому "рыночному прецеденту", так как получение лицензий от множества правообладателей займет слишком много времени.

"Единственное, что отделяет нас от уровня ChatGPT - это буквально объем данных", - заявил на одном из совещаний Ник Грудин, вице-президент по глобальному партнерству и контенту. По его мнению, Meta* может опереться на решение суда по делу "Гильдия авторов против Google" от 2015 года. Тогда Google отстояла свое право сканировать, оцифровывать и каталогизировать книги в онлайн-базе, доказав, что использовала лишь фрагменты произведений, трансформируя их и создавая новый продукт, что подпадает под принцип "добросовестного использования".
Однако этические вопросы никуда не исчезли. Как рассказал один из сотрудников, даже на встрече с участием Криса Кокса, главного директора по продуктам Meta, никто не озаботился тем, насколько честно и правильно использовать творческий труд людей без их ведома и согласия.
Похоже, в Meta* решили идти по стопам OpenAI и Google, не считаясь с правами авторов. Гонка ИИ-вооружений набирает обороты, и все средства хороши в борьбе за лидерство. Но сумеет ли Марк Цукерберг найти баланс между жаждой прогресса и этикой? Или погоня за "цифровой кровью" для ИИ-моделей окончательно затмит в его империи все моральные ориентиры? Пока страсти вокруг ИИ накаляются, нам остается лишь гадать, какие еще границы готовы переступить техногиганты в стремлении к технологическому превосходству.

В то время как Meta* и Google лихорадочно ищут новые источники "цифровой крови" для своих ненасытных ИИ-моделей, Сэм Альтман из OpenAI предлагает иной подход к решению надвигающегося кризиса данных.
По его мнению, которое он озвучил на майской конференции, компании вроде OpenAI в конечном итоге начнут обучать свои алгоритмы на текстах, сгенерированных самим ИИ - так называемых синтетических данных. Идея проста: если ИИ-модель способна создавать правдоподобные тексты, то она может сама производить дополнительную информацию для своего развития. Это позволит разработчикам создавать все более мощные системы, не завися от защищенных авторским правом материалов.
"Как только мы преодолеем горизонт событий синтетических данных, и модель станет достаточно умной, чтобы генерировать качественную информацию, все будет в порядке", - заявил Альтман.
Однако концепция синтетических данных, хотя и не нова, таит в себе немало подводных камней. Исследователи бьются над этой проблемой годами, но создать ИИ, способный эффективно обучать самого себя, оказалось очень непросто. Модели, которые учатся на собственных результатах, рискуют попасть в замкнутый круг, где они лишь усиливают свои причуды, ошибки и ограничения.
"Данные для этих систем - как тропа через джунгли, - говорит Джефф Клун, бывший исследователь OpenAI, ныне преподающий информатику в Университете Британской Колумбии. - Если они будут обучаться только на синтетической информации, то рискуют заблудиться в этих дебрях".
Чтобы избежать этой ловушки, OpenAI и другие компании изучают возможность совместной работы двух разных ИИ-моделей. Одна система генерирует данные, а вторая оценивает их качество, отделяя зерна от плевел. Впрочем, исследователи расходятся во мнениях, насколько эффективным окажется такой подход.
Но топ-менеджеры ИИ-индустрии уже мчатся вперед на всех парах. "Все должно быть в порядке", - уверенно заявляет Альтман.

Возможно, синтетические данные действительно помогут техногигантам преодолеть кризис "цифровой крови" и вывести ИИ на новый уровень. Но не приведет ли погоня за искусственным разумом, способным воспроизводить самого себя, к непредсказуемым последствиям? Не заблудятся ли наши ИИ-помощники в дебрях собственных алгоритмов, оторвавшись от реальности и потеряв связь с миром людей?
Гонка за "цифровой кровью" и стремление к созданию все более мощных ИИ-систем ставит перед человечеством непростые вопросы. Готовы ли мы пожертвовать приватностью, авторскими правами и этическими принципами ради технологического прогресса? Сможем ли мы сохранить контроль над своими творениями, когда они начнут воспроизводить сами себя? Опасность потерять ориентиры в цифровых джунглях искусственного интеллекта еще никогда не была столь реальной. Но одно можно сказать наверняка: мир уже никогда не будет прежним. Мы стоим на пороге новой эры, где границы между человеческим и машинным интеллектом становятся все более размытыми. И только от нас зависит, сумеем ли мы направить эту революцию в нужное русло и извлечь из нее максимум пользы для всего человечества.

Причем каждый из нас может внести свой вклад в эту дискуссию - делитесь своими мыслями в комментариях и ставьте оценки этой статье, ведь именно наши с вами комментарии повлияют в конечном счете на обучение какой-нибудь языковой модели.
Я рассказываю больше о нейросетях и делюсь иллюстрациями у себя на YouTube, в телеграм и на Бусти. Буду рад вашей подписке и поддержке.
*Meta и соцсети компании Facebook и Instagram признаны экстремистскими и запрещены в РФ.
На Украине продолжаются активные разговоры о запрете телеграма. На этот раз власть имущие даже попытались перейти от слов к действиям. Так, глава комитета Рады по свободе слова Ярослав Юрчишин рассказал, что они запустили проверку телеграма в налоговой, а также обратились администрацию платформы с просьбой заблокировать ряд телеграм-каналов. А один из нардепов предложил законопроект, который может запретить использование телеграма государственным органам. «МК» разбирается, к чему это может привести.

ФОТО: UNSPLASH.COM
За последние две недели дискуссии о том, что же делать с телеграмом, снова активизировались. Сначала глава ГУР Кирилл Буданов (внесен в список террористов и экстремистов Росфинмониторинга) заявил, что телеграм – это «проблема национальной безопасности». «Я абсолютно против притеснений свободы слова, но это уже слишком. То есть у нас любой человек может сделать канал, начать там писать все, что заблагорассудится, а когда что-то начинают делать, прикрываться тем, что это свобода СМИ. Но это не свобода СМИ, это немного иначе называется», - сказал Буданов. Как именно «немного иначе называется» он не уточнил.
Снова заявила о себе и СБУ, мол, телеграм сотрудничает с ФСБ, поэтому он опасен для граждан Украины. «Прежде всего, СБУ отслеживает, где находятся серверы телеграма. Есть высокая вероятность, что они — на территории России. Вторая проблема телеграма — его владелец и разработчики являются гражданами России. Третья — мы видим четкое сотрудничество телеграма с Роскомнадзором и ФСБ. Когда нужно ФСБ заблокировать любой канал на территории России, телеграм выполняет эти указания моментально», — заявил представитель департамента контрразведывательной защиты интересов государства в сфере информбезопасности СБУ Александр Мельниченко.
А как вишенку на торте «РБК. Украина» выпустили интервью с главой комитета Рады по свободе слова Ярославом Юрчишиным, который заявил, что блокировка телеграма – это совсем не ограничение свободы слова. «Свобода слова – это производная от персонализации, то есть мы понимаем, кто стоит за этим словом. И соответственно, когда это слово нарушает законные рамки, например, раздается призыв к терроризму или оправданию российской агрессии, то надо понимать, что твое слово приводит к определенным последствиям», - объяснил глава комитета Рады по свободе слова.
Также он рассказал, что со стороны СБУ был направлен запрос об удалении 26 телеграм-каналов, среди которых известные «Легитимный» и «Резидент». Закрыть их пытались и ранее. В 2021 году Киевский районный суд Харькова постановил заблокировать ряд телеграм-каналов, среди которых были и «Резидент» с «Легитимным». Как мы видим, блокировка не удалась. На каждом из каналов сейчас чуть больше миллиона подписчиков.
Однако СБУ сообщает, что ряд телеграм-каналов уже был удален по их требованию. «У нас с ними постоянно идут переговоры, я бы не хотел раскрывать детали, но определенные сдвиги в этом направлении есть. Некоторые Telegram-каналы в Украине уже заблокированы, некоторые могут быть заблокированы вскоре», — рассказал начальник Департамента кибербезопасности СБУ Илья Витюк. Какие именно каналы оказались заблокированы, Витюк не рассказал. Администрация телеграма эту информацию также не подтверждала. Зато на его слова довольно скоро отреагировали журналисты, которые нашли у супруги главы департамента квартиру за более 21,5 млн гривен. При этом в его декларации она стоит 12 млн, а зарплата Витюка составляет 1,8 млн грн в год. Иронично, что информация довольно быстро распространилась как раз по телеграм-каналам, которые оказались «в зоне риска» для блокировки.
Кроме удаления каналов, Юрчишин выдумал еще один способ, как можно повлиять на телеграм. Он сообщил, что его комитет уже обратился в Государственную налоговую службу относительно того, платит ли телеграм налоги. «Мы обратились относительно того, платит ли телеграм налоги. И какие шаги налоговая служба планирует предпринять для того, чтобы телеграм все же платил согласно "закону О Google" (закон, обязавший крупные технологические компании вроде Google, Amazon платить 20% налога на добавленную стоимость – авт..)», - рассказал Юрчишин.
Параллельно с различного рода заявлениями в Верховную Раду был внесен законопроект по контролю телеграма. Его внесла группа депутатов во главе с нардепом Княжицким и главами комитета по свободе слова Юрчишиным и гуманитарной политики Потураевым. В пояснительной записке они пишут, что Закон о медиа не регулирует деятельность платформы общего доступа телеграм, что предлагается исправить. В частности, платформу хотят обязать удалять контент телеграм-каналов по требованию Нацсовета по телевидению и радиовещанию (то есть без какого-либо решения суда).
Кроме того, депутаты предлагают ввести в законодательство термин непрозрачной платформы общего доступа (НПСП). Под это определение относятся те платформы, о которых у украинского медиарегулятора нет сведений о представителе в Украине или об открытом представительстве в любом государстве - члене ЕС. Под эту категорию подпадают также платформы, которые не предоставят документы по запросу Национального совета в установленный срок.
В случае принятия законопроекта, законодатели хотят запретить использовать НПСП государственным организациям, банкам, органам гос власти и местного самоуправления и т.д. При этом, согласно опросам, 72% украинцев получают новости именно через телеграм. А при запрете на использование телеграма органы государственной власти потеряют как минимум 20% своей аудитории.
Так какое же решение найдут власть имущие на Украине? Попытаются заблокировать или все-таки успокоятся? Об этом мы спросили у политического эксперта, журналиста издания «Украина.ру» Василия Стоякина:
«Эта проблема в принципе нерешаема. Мы же в России это уже проходили, пытались его запретить, но ничего не получилось. То, что предложил Княжицкий, в общем-то, выглядит логично и понятно. То есть действительно для государственных органов использовать телеграм как систему связи и общения, наверное, неправильно. Это слишком свободная платформа для такой специфической сферы как госуправление. Логика в этом есть.
Что касается возможности заблокировать те или иные телеграм каналы, то они тоже не особо блокируются. Если администрация телеграма на это пойдет, господину Дурову для этого нужны какие-то очень серьезные мотивы. Например, после теракта в Крокусе мотивы у него появились моментально. Меры были приняты немедленно. А в случае с Украиной, с чего бы ему заботиться о потребностях киевского режима?
В остальном – ну, нельзя его запретить. Ничего не получится. Люди будут все равно выходить на него через VPN. Почему это делается – понятно. Хочется отключить все альтернативные точки зрения, потому что телеграм не делится на «хороших» и «плохих». Полагаю, в итоге это закончится тем, что они будут продолжать рассказывать, что телеграм – это плохо, там сидит российская пропаганда, но чтобы это вышло в какие-то реальные рамки – вряд ли».
Источник:
Пролетел пост про то, что в гугл картах Крымский мост написан по-украински. Смахнула не туда, потеряла пост. Но хочу поделиться своим опытом перлов от гугл.
Делала недавно запрос, немного удивилась
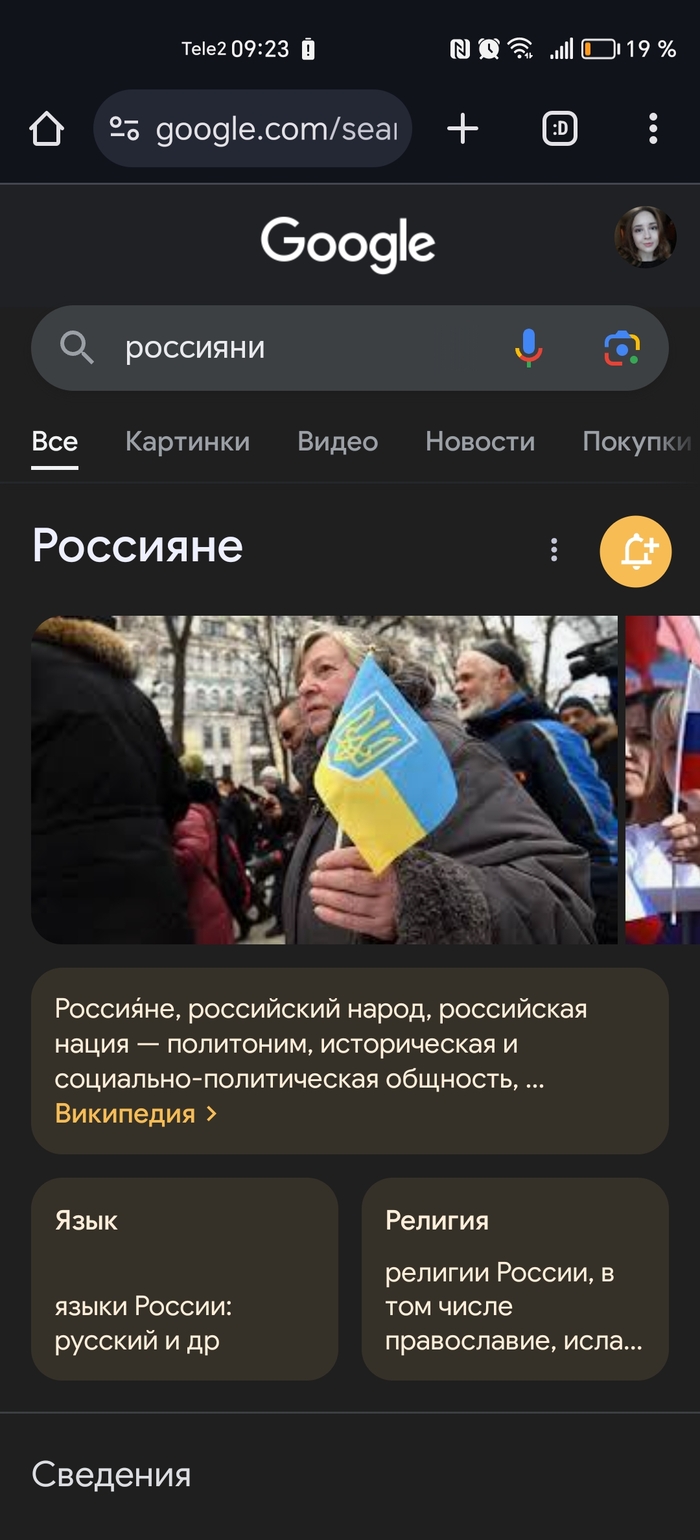
А вообще всегда поражало, что во всем виноваты русские. Русские то, русские это. Но погодите, в России более 140 народов, че все русские-то. А потом пришла мысль. Ведь английское слово russians переводится и как русские, и как россияне. Но не все русские россияне и не все россияне русские, но почему-то во всем винят именно последних. Ладно украинцы, им методички не адаптировали, а почему наши так постоянно переводят? Или только меня это смущает?










