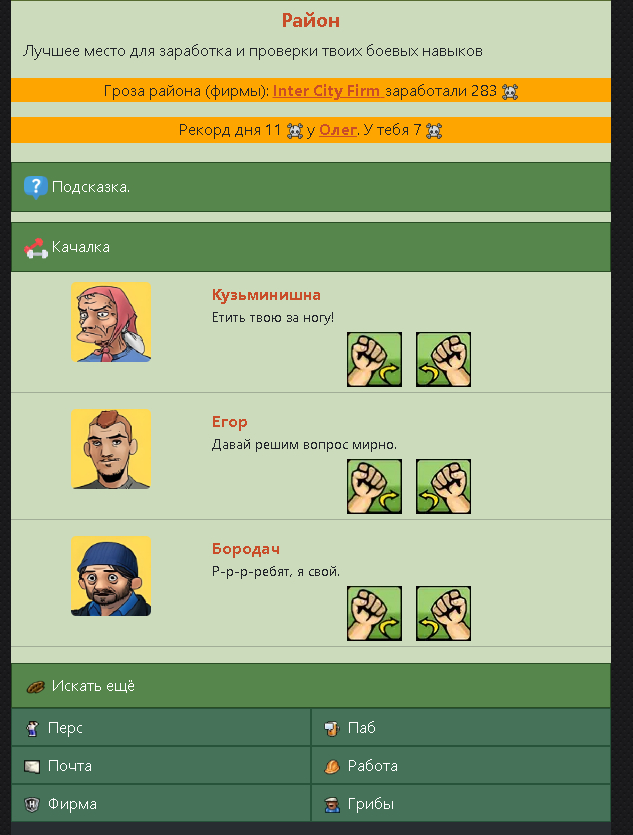
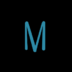Всем привет. Возможно я выложу таких несколько постов. Мы ищем программиста готового повторить старую .mobi игру. Как раньше существовали порталы Wap на которых и игры размещались и тд по типу Tegos. Нужно создать онлайн игру вот как она должна выглядеть:
Сделать нужно красиво, чтобы смотрелось не вырвиглазно. Был интузиаст который пытался разрабатывать игру один, но вот результат
ЕСЛИ ВЫ ГОТОВЫ ВЗЯТЬСЯ ЗА РАБОТУ. НАПИШИТЕ СВОЙ ТЕЛЕГРАММ ПОД ЭТИМ ПОСТОМ. РЕШИМ ВОПРОС С ЦЕНОЙ.ЖДУ НАДЕЮСЬ НАЙДЁТСЯ ЧЕЛОВЕК.
Всем привет. Относительно недавно мне стало интересно написать свой фреймворк для 2д игр, чтобы собственно их и создавать. Пишу всё это дело на java - вот скриншот типичного кода:
Внутренности
И вот, что мы получаем:
Результат
Я также написал примитивный модуль для физики, всё это можно найти в документации.
Если вам интересно, можете посмотреть проект здесь.
В предыдущих частях мы познакомились с рекурсивным подходом решения деревьев. В этой части мы воспользуемся стэком.
Рекурсия далека от идеала.
Рекурсия чаще всего используется только во время собеседований (а этот цикл статей именно направлен на подгтовку к собеседования). В промышленной разработке её чаще избегают изза потенциальных следующих потенциальных проблем:
Криво написанная рекурсия может выполняться бесконечно (в "лучшем" случае это приведет к ошибке переполнения стэка). В худшем программа повиснет (особенно если программа однопоточная).
Изначально чаще всего под стэк выделяется не более 1мб памяти а это значит что рекурсивная функция сможет вызвать саму себя где то от 10 до 20 тысяч раз. (размер можно легко увеличить с помощью параметра -Xss но стоит помнить что у JDK есть ограничения по верхней границе - обычно до 1 ГБ)
Рекурсия сложна для понимания, особенно новичкам.
Высокое потребление памяти - каждый раз спуская на уровень ниже мы позволяем сборщику мусора удалить ссылки используемые на верхних уровнях - и это не ошибка тк все объекты используемы выше текущего уровня будут использованы когда мы вернемся "снизу"
Очеред (или Стэк) - популярный подход в решении задач на деревья.
Во многом, задача на деревья определяется тем, как мы можем проитерироваться по всем узлам. В рекурсии мы вызываем рекурсивную функцию и передаем ей наследники. В случае же с очередью или стэком мы используем следующий трюк:
Добавляем корневой элемент в очередь
Проходим по всем элементам очереди и ранее добавленные узлы
Если наследники узла не пусты добавляем в очередь опять
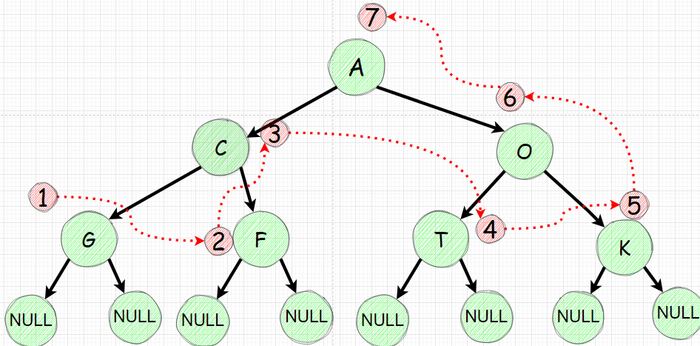
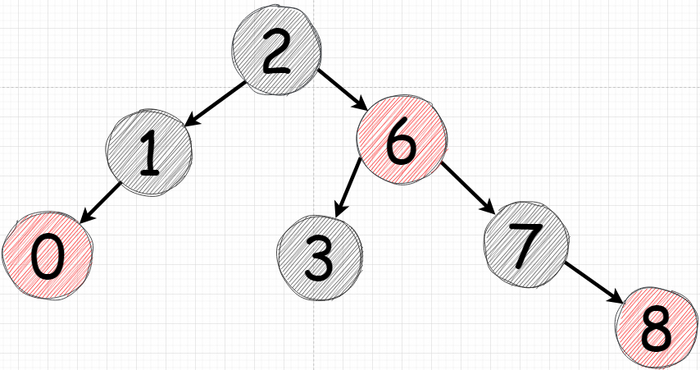
Обходим дерево в ширину.
Распечатаем все значения дерева сверху вниз, распечатывая значения на каждом уровне слева направо, как гирлянду.
Желаемый порядок распечатки - сверху вниз, слева направо.
Что такое очередь и как ей пользоваться?
Для начала познакомимся с интерфейсом очереди (Queue) в Java. Очередь представляет собой FIFO (first in, first out - первый зашёл, первый вышел) структуру. В нашем случае потребуется два метода:
add - добавить в очередь
poll - вытащить первого из очереди (элемент который бы добавлен раньше других)
Как именно мы будем выполнять обход дерева?
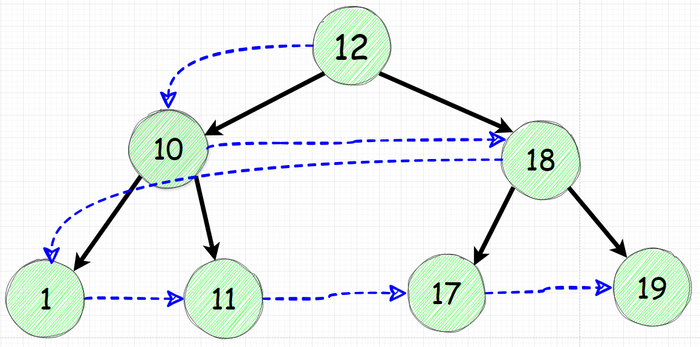
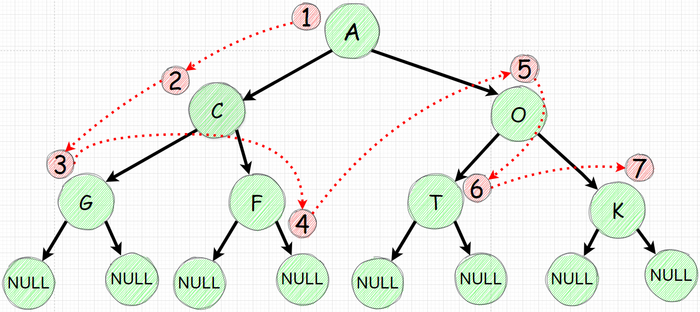
Обходить дерево мы будем следующим способом:
Добавим в очередь корневой элемент
"Вытащим" добавленный элемент и положим в очередь его наследников
Повторим 1-2 шаги пока в очереди ничего не останется
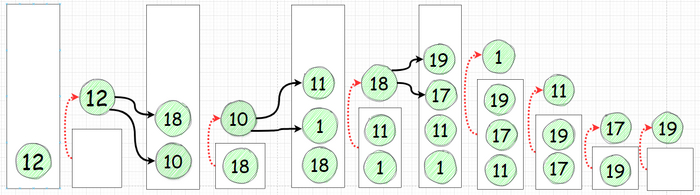
Изобразим эти действя по шагам:
Движемся слева направо. Красными стрелками указаны "вытаскиваемые" из очереди элементы.
На графике выше вы могли бы заметить, что после момента добавления 4-х элементов больше элементы не добавляются, так как у каждого из 4-х узлов нет наследников.
Теперь напишем код описанной выше логике
И так как запомнить данный подход если он попадется на собеседовании? Я бы рекомендовал держать в памяти две вещи:
условие while (!queue.isEmpty())
queue.poll() - вытаскивание элемента
В следующих статьях мы будем использовать очередь для решения задач, связанных с деревьями. Кому интересна промышленная разработку приглашаю в котовскую телеграм группу
Их есть у нас! Красивая карта, целых три уровня и много жителей, которых надо осчастливить быстрым интернетом. Для этого придется немножко подумать, но оно того стоит: ведь тем, кто дойдет до конца, выдадим красивую награду в профиль!
Эта часть является продолжением цикла лекций про деревья. В этой части мы снова воспользуемся рекурсией чтобы инвертировать дерево. Задача довольно популярна и по сложности является довольно простой.
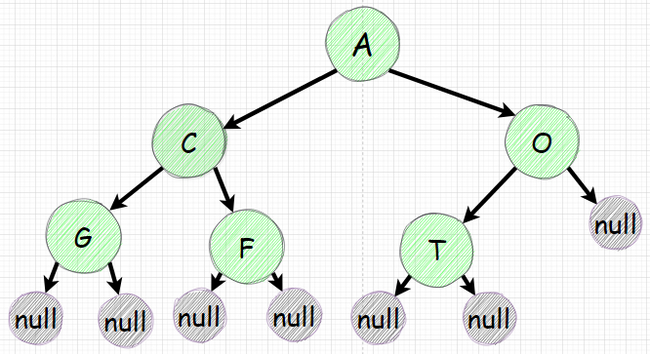
Допустим у нас есть дерево
Допустим у нас есть дерево ниже:
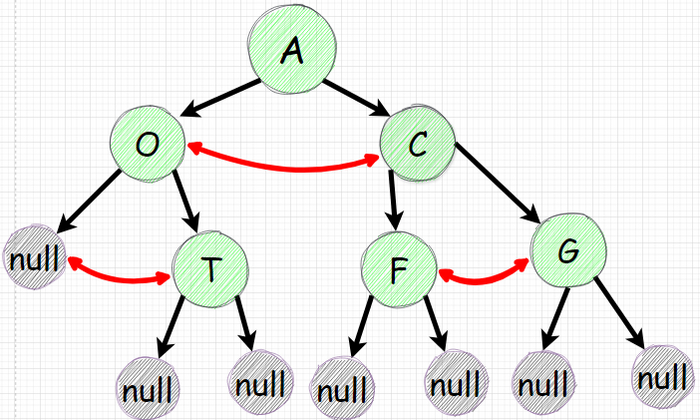
Инвертируем дерево
Целью является инвертировать дерево. Те для каждого узла нужно поменять местами его левый и правый наследники. Логику надо также применять к наследникам наследников.
Давайте проговорим какие этапы нужно продумать:
Проитерироватсья по всем узлам рекурсией те нам понадобится функция которая будет вызывать саму себя.
Нижние пустые null узлы нужно будет проигнорировать
Для всех остальных узлов нужно выполнить смену ссылок для правого и левого наследников
Решение:
Думаю вам тоже задача показалось довольно простой но при этом она является одной из самых частых во время собеседований. В следующей статье мы рассмотрим более сложные случаи. Всем кому интересно - добро пожаловать в мою группу.
В прошлой части мы рассмотрели разные подходы рекурсивного обхода дерева. Давайте воспользуемся некоторыми из них для решения довольно известных задач.
Находим максимальную глубину дерева.
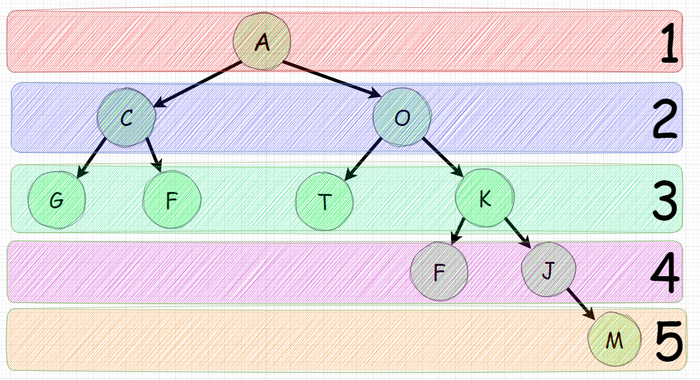
Одна из самых популярных и простых задач на деревья - поиск узла находящегося на максимально удаленом расстоянии. Рассмотрим дерево ниже:
Высота данного дерева - пять
Довольно очевидно что самый длинный узел в данном дереве - M и он является пятым по счету если головной является первым.
Как решать данную задачу используя рекурсию.
Если сильно упрощать то нам нужно сделать 2 действия:
Обойти все узлы
Каким то образом "сохранять" состояния каждый раз когда мы обходим узлы
Но как же сохранять состояния о той глубине на которой мы побывали? Тут есть как минимум два варианта:
Использовать возвращемое значение самой рекурсивной функции и "возвращать" её на уровень выше.
Иметь какой то объект в котором мы будем сохранять состояния находясь внутри рекурсии
Воспользуемся первым подходом. Сосредоточимся на следующих аспектах:
Рекурсивная функция должна передавать значение сама себе "наверх"
Определить какое именно значение должно перебрасываться.
Логика передаваемого "наверх" значения.
Самые нижние уровни (те что указывают на null) должны возвращать 0 тк они не включены в расчет глубины данного подграфа
Нижний уровень который с листьями имеет лишь null предков должен вернуть 1 тк он является первым уровнем
Узел выше чем 1й (те не лист) должен выбирать максимальный уровень из двух его наследников и добавлять 1 тк находится на уровень выше из наибольшего из них.
После данных рассуждений у нас вырисовывается вот такая картина:
null уровни 0, листья 1 и все остальные узлы - выбирает наибольшее из наследников и добавляют 1.
К чему привели наши рассуждения?
Все эти рассуждения намекают что в нашей итеративной функциии будет 3 разных сценария и функция которая выбирает наибольшее из двух. Именно подобные размышления чаще всего помогают перевести абстрактные размышления в код.
И так первая версия кода:
Версия рабочая но слишком многословная - хотя для собеседования вполне подойдет.
Самый важная часть кода - итеративный вызов левого и правого поддерева и последующий расчет максимального значения среди них. И конечно же добавление 1 наибольшему из них чтобы учесть и текущую высоту.
Этот код можно было бы улучшить удалив случай когда мы находимся в самом низу - дело в том что если условие истино то возвращаемое значение maxDepth + 1 будет также равно 1.
В прошлой части мы ознакомились с базовыми понятиями деревьев и обошли одно дерево рекурсией. В данной статье мы еще раз рассмотрим понятие рекурсии и посмотрим как небольшие во время итерации могут повлиять на результат. В данной части мы сфокусируемся на итерации, а в следующе мы уже будем использовать эти подходы для решения задач.
Обход деревьев часто ощущается как лабиринт
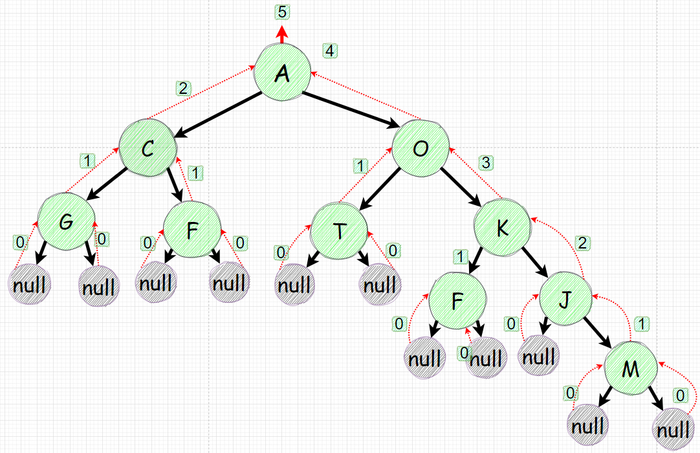
Давайте рассмотрим уже знакомое дерево:
Прямой обход дерева (Префиксный) - NLR
В прошло части мы уже итерировались по дереву рекурсивно. В нем мы сначала печатали значение узла (Node) затем посещаем левое поддерево (Left) и лишь потом правое поддерево (Right). Такой подход называется прямым или еще префиксным - NLR.
Распечатка значения и последующее движение влево вниз и уже затем вправо.
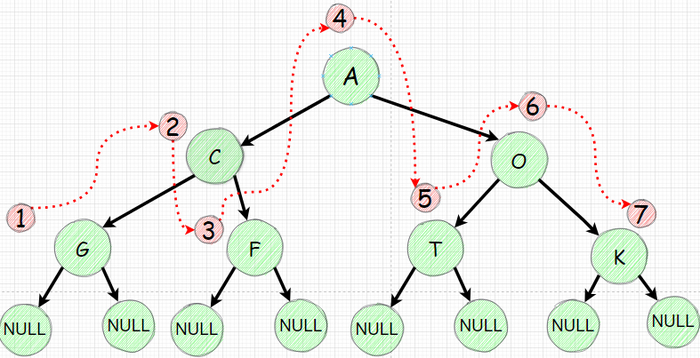
Центрированный обход дерева (Инфиксный) LNR
Теперь сделаем одно минимальное изменение - сначала мы пойдем в левое поддерево (Left) затем распечатаем значение узла (Node) и потом пойдем в правое поддерево (Right) - этот обход называют Инфиксным (от лат. in внутри fixus закрепленный) или центрированным - LNR. Понятие инфиксный прошло из математики. Если очень упрощать значит что N находится между L и R.
разница лишь в 1 линии но процес "обхода" меняется.
И так вроде рекурсия выполнила ровно такой же обход, но теперь процесс распечатки значения узла мы стали делать после того как уходим "влево". Теперь если задуматься то первая печать произойдет лишь когда мы дойдем до нижнего левого узла. Давайте изобразим как будет выглядеть "обход" а порядок печати значений узлов:
Обратный или Постфиксный обход. LRN
Думаю уже понятно что данный подход подразумевает печать значения узла (Node) после посещения левого (Left) поддерева и правого (Right) поддерева - LRN
Печатаем лишь после обхода левого и затем правого поддеревьев.
Порядок распечатки изображен ниже:
Минимальные изменения - большие последствия.
Изза минимальных изменений (меняя лишь порядок одной строчки) мы получили разные обходы дерева. Это позволит нам решать разные задачи в будущем.
Следующий этап.
В следующей статье мы рассмотрим какие задачи мы можем решать используя описанные подходы. Одна из главных целей цикла статей - помочь преодолеть страх задач про деревья во время собеседований. Думаю стоит повторить еще раз - как только вам прилетела задача на деревья во время собеса начинайте с того что напишите функцию обхода. Большинство алгоритмических задач решается именно через рекурсию (но не только через неё).
Выспаться, провести генеральную уборку, посмотреть все новые сериалы и позаниматься спортом. Потом расстроиться, что время прошло зря. Есть альтернатива: сесть за руль и махнуть в путешествие. Как минимум, его вы всегда будете вспоминать с улыбкой. Собрали несколько нестандартных маршрутов.
Деревья являются одним из самых пугающих вещей в разработке. Еще хуже дело обстоит, когда программист встречает задачу, связанную с деревьями, во время собеседования. В этой статье я постараюсь минимизировать боль, связанную с этой темой.
Деревья бывают разные. Мы рассмотрим двоичное сбалансированное.
В данной статье мы рассмотрим наиболее популярные — двоичные сбалансированные (красно-черные) деревья.
Пример бинарного дерева. У каждого листка может быть не более двух наследников.
Основные понятия.
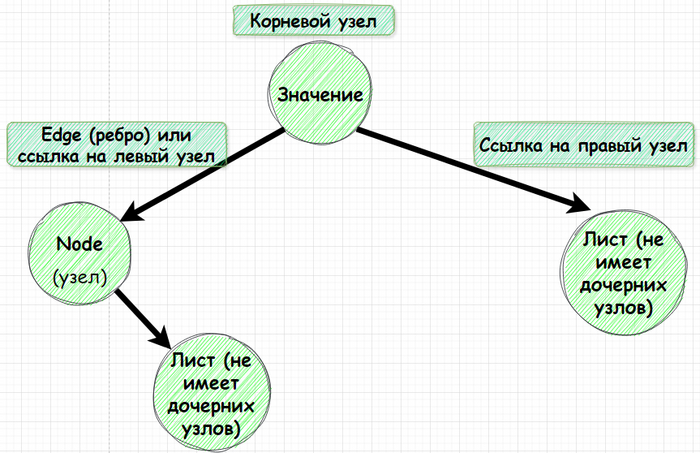
Рассматривая бинарные деревья нужно знать следующие понятия:
Node - он же узел. Это элемент дерева, содержащий какое-то значение, которое может быть любым, от примитива (например, числа) до объекта (например, пользователя).
Edge или ребро. Ссылка, соединяющая один узел с другим или указывающая на пустое значение (null).
Root Node. Верхний узел дерева, от которого начинается вся структура.
Leaf - Узел, не имеющий наследников, то есть находящийся в самом низу иерархии.
Высота дерева - Количество "уровней", от корня до самого нижнего узла.
Несбалансированные деревья могут выродиться в связный список.
Несбалансированные деревья — это деревья, у которых высота левой и правой веток может значительно отличаться. В худшем случае все узлы могут располагаться по одной стороне. В этом случае дерево деградирует до связного списка.
деградированное дерево вырожденное в связанный список.
Сбалансированные деревья.
Сбалансированные (например красно-черные) при каждом добавлении нового узла проверяют, является ли дерево "несбалансированным". Если условие истино то дерево делает "разворот" свои узлов.
Пример красно черного сбалансированного дерева. Именно такое используется в TreeMap
Сбалансированные деревья никогда не вырождаются в связанные списки. В J ava джаве деревья представлены коллекцие TreeMap и TreeSet (который инкапсулирует TreeMap внутри себя).
Как могут быть представлены деревья на уровне кода.
Если мы не используем готовые решения вроде TreeMap то простейшее дерево может быть представлено в виде следующего класса:
Простейший узел. По большому счету это единственный важный момент.
Итого что мы имеем:
String data это то значение которое хранит узел. Это может быть любым объектом - в нашем случае просто строка.
Node left - ссылка на левого наследника.
Node right - ссылка на правого.
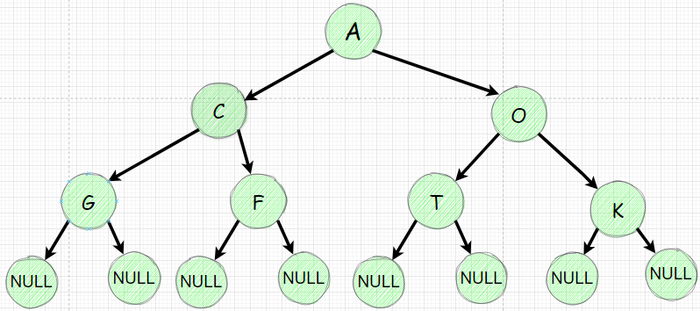
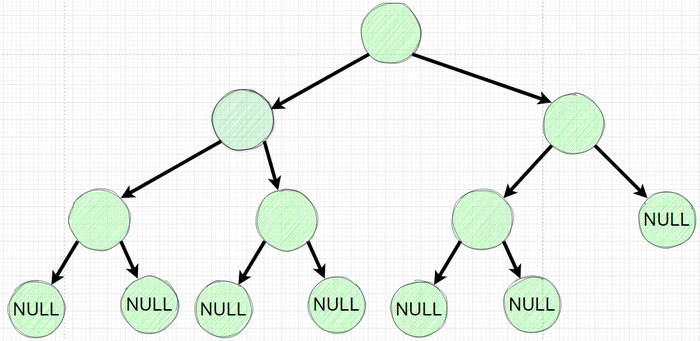
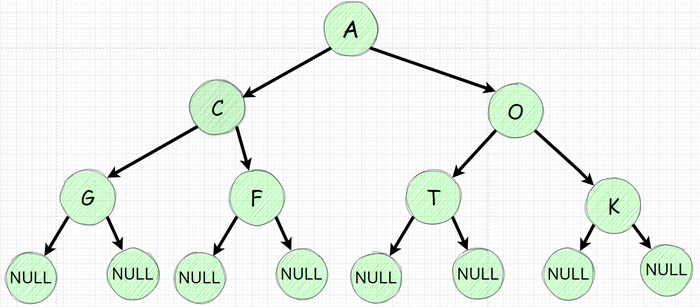
Используя Node класс создадим дерево
Поочередно инициализируем наше дерево с 7 узлами
Изобразим полученное дерево:
Итерация по дереву - один из самых важных навыков для решения задач.
Большинство (если не все) задач, связанных с деревьями требуют итерации или обхода узлов. Чаще всего, умея обходить дерево, вы решаете львиную часть проблемы. В данной статье мы рассмотрим лишь 1 вариант итерации, я напишу отдельные статьи чтобы рассмотреть другие подходы.
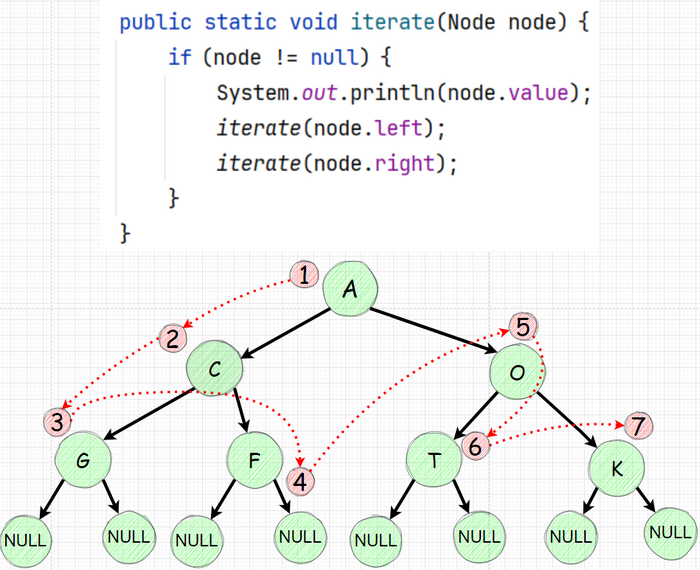
Используем рекурсию для итерации и распечатки всех элементов.
Каждый раз когда вам прилетела задача по деревьям, помните - скорее всего в основании решения будет рекурсия (это не всегда так, но довольно часто). Те у вас будет функция которая будет вызывать сама себя. Для распечатки дерева напишем рекурсию которая обходит все элементы начиная с левого наследника:
Код вроде простой но не стоит его недооценивать. Давайте проговорим этапы:
Распечатываем значение узла
Идем к левому наследнику и повторяем действие (те опять распечатываем и идем влево)
после того мы обошли все левые и уткнулись в null мы "возвращаемся" на уровень который находится наверху от нижнего левого и идем в правый наследник
зайдя в правый распечатывем и идем влево повторяя шаги 2-3.
Все это звучит странно проще будет изобразить:
Это лишь первая статья но в ней мы ознакомились с основными понятиями. Также мы обошли дерево, используя рекурсию. Это один из самых популярных подходов в решениии подобных задач. В следующей части мы рассмотрим альтернативные варианты работы с деревьями.