




Ученые Гарварда фальсифицировали результаты исследований лечения рака

Американский центр исследования рака, связанный с Гарвардским университетом, отозвал шесть исследований и исправил десятки других после того, как британский ученый обнаружил, что их авторы фальсифицировали данные, отфотошопив изображения образцов клеток и результаты тестов.
В заявлении, сделанном в понедельник, онкологический институт Дана–Фарбер в Бостоне сообщил, что пересматривает 50 научных работ, написанных четырьмя ведущими учеными института, включая его руководителя доктора Лори Глимчера и главного операционного директора доктора Уильяма Хана.
По словам представителя Дана–Фарбер, шесть исследований "подлежат опровержению", 31 работа "признана заслуживающей исправления", а еще одно исследование "находится на стадии проверки" на предмет наличия ошибок.
Предполагаемые фальсификации были обнаружены британским молекулярным биологом Шолто Дэвидом, который опубликовал их в своем блоге. Дэвид обнаружил, что изображения в работах были растянуты или откровенно "скопипащены", чтобы подделать результаты тестов.
В одном случае фотография четырех лабораторных мышей, сделанная в первый день исследовательского проекта, была скопирована и представлена как фотография, сделанная на 16–й день проекта, в явной попытке ложного утверждения, что определенное лечение остановило развитие опухолей.
В другом случае доктор Хан подделал результаты многочисленных анализов "Вестерн–блот", которые используются для обнаружения специфических белков, связанных с раком, аутоиммунными заболеваниями и прионными расстройствами.
"Миллиарды долларов на онкологию были выброшены на помойку, но благодаря этому многие академики сделали карьеру, некоторые стали очень богатыми, а в Дана–Фарбер обосновались целые династии", — написал Дэвид в своем блоге.
Дана–Фарбер оспорили некоторые выводы Дэвида, а их представитель заявил, что некоторые из приведенных данных были получены в сторонних лабораториях и что "несоответствия в изображениях" часто могут быть ошибочно приняты за намеренные подделки. Пресс–секретарь не уточнил, относится ли это к конкретным "расхождениям", на которые ссылается Дэвид.
Дана–Фарбер является учебным филиалом Гарвардского университета, а все четыре исследователя, обвиненные в мошенничестве, являются преподавателями Гарвардской медицинской школы. Новости о предполагаемых подделках появились после крупного скандала с плагиатом в университете, когда президент Гарварда Клодин Гей была обвинена в более чем 50 случаях академического воровства, в том числе в своей докторской диссертации.
Хотя в декабре внутреннее расследование признало Гей виновной в "неправомерном поведении исследователя", критики утверждают, что университет поспешил с расследованием, пытаясь защитить Гей. После появления новых обвинений в академическом мошенничестве Гей ушла в отставку в начале этого месяца, пробыв на посту президента самый короткий срок за всю 388–летнюю историю Гарварда.
Показать полностью
1


Живучесть научных фальсификаций на примере рисунков Геккеля
Доходит до полного абсурда: всем известно, что Эрнст Фридрих Филипп Август Геккель (1834-1919), автор терминов «экология» и «питекантроп», совершил ряд подтасовок и прямых фальсификаций.

1 Геккель на Цейлоне, 1882 год
Геккель сформулировал биогенетический закон — по его мнению, в развитии каждого организма он проходит этапы эволюции всего вида. В своей книге Геккель изобразил зародыши восьми видов позвоночных на разных стадиях развития. Иллюстрации показывали: человеческий эмбрион — сначала беспозвоночное существо, затем рыбка с жаберными щелями, собачка с хвостом, обезьянка, покрытая шерстью, и лишь потом человек.
Опираясь на свои эпохальные открытия, Геккель построил даже генеалогическое дерево животного царства.
Эти иллюстрации были опубликованы несколько десятков миллионов раз, в том числе в учебниках для школ и вузов.
... А самое интересное вот в чём: учёный совет университета Иены официально признал Геккеля виновным в научном мошенничестве. Оказалось, Геккель рисовал зародыши не такими, какими они были, — а такими, какими ему хотелось. Так сказать, для подтверждения теории.
Геккель был вынужден уйти в отставку и до конца жизни не преподавал. Он развивал теорию «монизма», причудливую научно-философскую теорию, призванную, по его мнению, заменить религию. Он даже создал международную «Лигу монистов», но безрезультатно: никто в его Лигу" не поспешил вступить.
Начиная с 1997 года в разных американских журналах печатаются статьи, разоблачающие рисунки Геккеля. В 1997-м в журнале «Anatomy and Embryology» была опубликована статья группы исследователей, которые сравнили рисунки Геккеля с современными фотографиями эмбрионов тех же животных на тех же стадиях развития. Ученые дружно пришли к выводу о том, что рисунки Геккеля не содержат множества важных деталей.
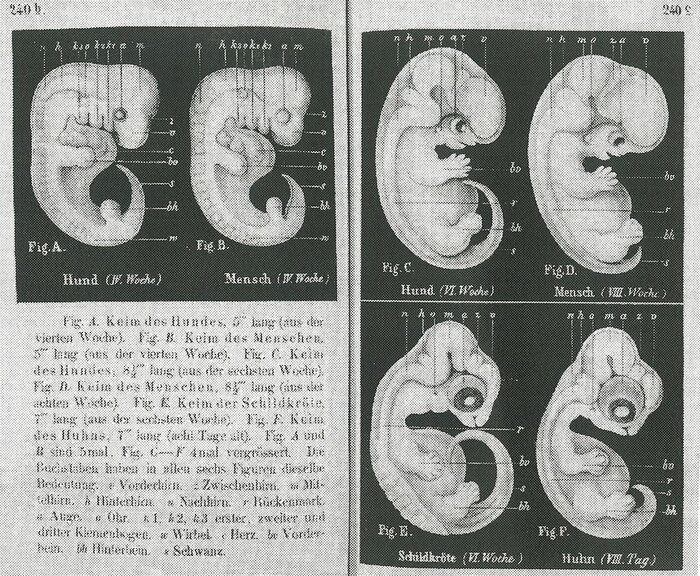
2 Иллюстрации эмбрионов, представленными Геккелем в 1868 году в качестве убедительного доказательства эволюции
Рисунки Геккеля были названы фальсифицированными и в обзоре по материалам этой статьи в журнале «Science» (Pennisi, 1997. 277:1435). А ведь «Science» — журнал для широких кругов научной общественности. В нем печатают то, что важно для учёных разных специальностей.
Но что самое невероятное: рисунки Геккеля не изымаются из учебников и монографий! Их продолжают воспроизводить. Геккеля упоминают в лекционных курсах и в книгах, аки великого ученого. Это в конце XIX века Геккеля попросту выперли из науки. В XXI веке он — что-то вроде научного святого, не подлежащего критике.
Мифология — в том числе и научная
Там, где нет твердого знания о чем-то, естественным образом появляются мифы. Древние греки рассуждали и спорили, что такое Млечный путь — молоко ли это козы Амальтеи, или молоко нимфы, которая превратилась в козу? Или это молоко богини Геры? Гера внезапно узнала, что младенец у её груди, Геракл, вовсе не её сын, а сын блудного Зевса и земной женщины. Гера оттолкнула Геракла, пролитое ею грудное молоко сделалось Млечным путём.
Буровский А.М., Неудобные вопросы к науке от профессора Буровского, М., «Тион», 2022 г., с.143-144
+ Ваши дополнительные возможности
1) Видео: МОДЕЛИРОВАНИЕ ЛИЧНОСТЕЙ до 1950 года
Источники фото
Показать полностью
2
1

Говорят, если гуманитарий пройдет это головоломку до конца, он может считать себя технарем
А еще получит ачивку в профиль. Рискнете?


Большой скандал в научном мире прямо сейчас. Часть 3
Это перевод третьей статьи из серии расследований Data Colada про фальсификацию данных в статьях профессора Гарвардской школы бизнеса Франчески Джино.
Напоминаю, что этот пост является моим вольным пересказом расследования Data Colada; все картинки тоже оттуда.
Погнали.
Часть 3: Обманщики вне порядка
В этот раз речь пойдет о статье Джино и Вильтермута «Злой гений? Как нечестность может приводить к большей креативности» [“Evil Genius? How Dishonesty Can Lead to Greater Creativity”], опубликованной в 2014 году, а именно об Исследовании 4.
Авторы расследования из Data Colada уточняют, что, по имеющейся у них информации, соавтор Джино не проводил и не помогал со сбором данных для эксперимента, о котором пойдет речь. База данных получена несколько лет назад напрямую от профессора Джино.
Что изучали?
Эксперимент проводился онлайн. Участники (178 человек) сначала выполняли задачу, в которой подбрасывали виртуальную монету и в которой можно было смошенничать. После этого участникам предлагалось два творческих задания. Далее сосредоточимся на результатах задачи «использования», в которой нужно было в течение 1 минуты придумать как можно больше творческих способов использовать газету (эта задача ранее применялась другими учеными как способ оценки креативности).
Что получили?
Гипотеза авторов подтвердилась: участники, которые сжульничали при подбрасывании монеты, придумали больше вариантов использования газеты (M = 8,3, SD = 2,8), чем участники, которые не обманывали (M = 6,5, SD = 2,3, p <,0001).
Но снова аномалия: неупорядоченные наблюдения
Как и в первой части расследования, фатальный признак фальсификации связан с сортировкой данных.
База практически идеально отсортирована по двум столбцам: сначала по столбцу «Обманывали», указывающему, обманывали ли участники в задаче на подбрасывание монеты (0 – не обманывали; 1 – обманывали), а затем по столбцу «Количество ответов», в котором указано, сколько вариантов использования газеты придумал участник.
Как и в первом расследовании, тот факт, что сортировка почти идеальна, и палит всю контору.
Давайте посмотрим, как сортируются данные. На приведенном ниже скриншоте показаны первые 40 наблюдений. Поскольку данные сначала сортируются по столбцу «Обманывали», все эти наблюдения представляют НЕмошенников, у которых, соответственно, в этом столбце 0 баллов. И далее они прекрасно сортируются по столбцу «Количество ответов» – все 135 человек.
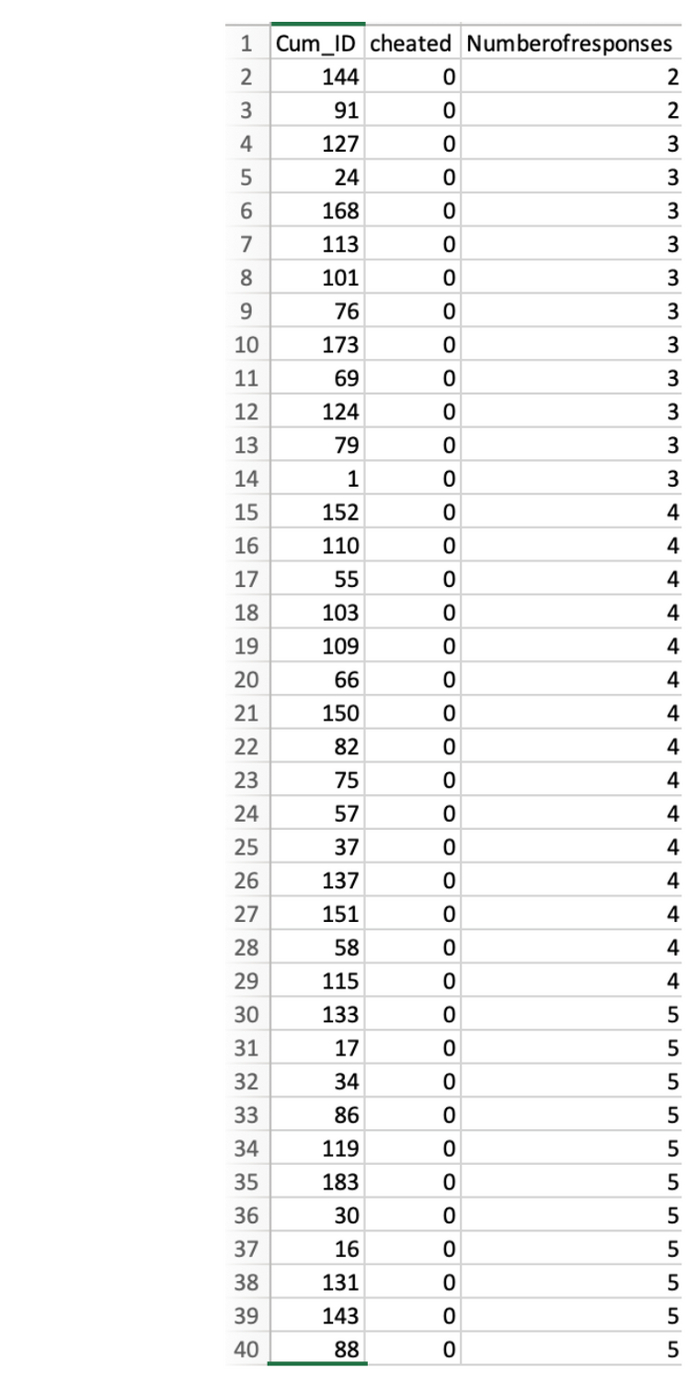
Посмотрим теперь на обманщиков.
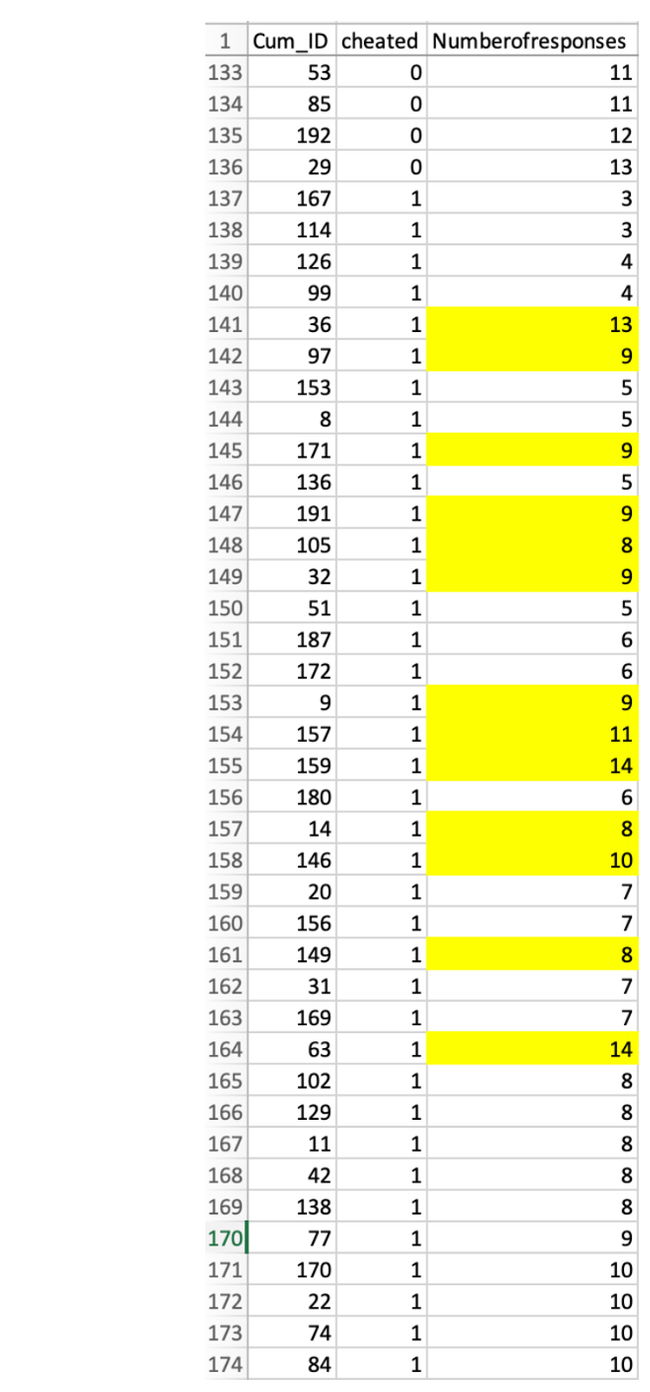
О нет: несмотря на то, то 43 обманщика также отсортированы по числу ответов, среди них есть 13 наблюдений, расположенных не в том порядке, в котором они должны быть.
Это дает основание заподозрить, что эти 13 наблюдений были изменены вручную после сортировки для получения желаемого эффекта.
Здесь важно отметить три вещи
1. Не представляется возможным отсортировать набор данных таким образом, чтобы получить порядок, в котором находились данные. Они либо были первоначально введены таким образом (что маловероятно, поскольку данные исходно были файлом Qualtrics [онлайн-платформы для исследований], который по умолчанию сортируется по времени), либо они были изменены вручную.
2. Напомним, что строки сортируются по столбцу «Количество ответов». Если значения, которые находятся не по порядку, были изменены, несложно выяснить, какими они были исходно. Например, в строке №141 есть «13». Строка над ней имеет «4», а первое по порядку значение после нее — «5». Следовательно, если данные были изменены, то можно предположить, что эта «13» раньше была либо «4», либо «5».
3. Появится чуть дальше, а сначала
Попробуем догадаться, как выглядели исходные данные
Ниже вы можете увидеть два новых столбца — «Предполагаемый минимум» и «Предполагаемый максимум», в которых есть два предполагаемых значения. В некоторых случаях точно известно, какое число менялось, в некоторых – оно находится в пределах ±1.
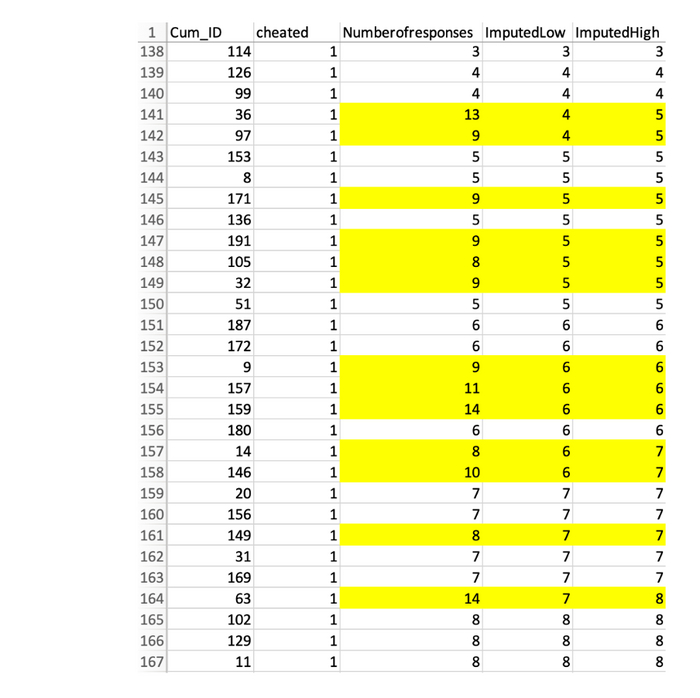
Посмотрим, есть ли различия между выложенным-сфальсифицированным датасетом (слева) и предположительно-реальным (справа) на графиках:
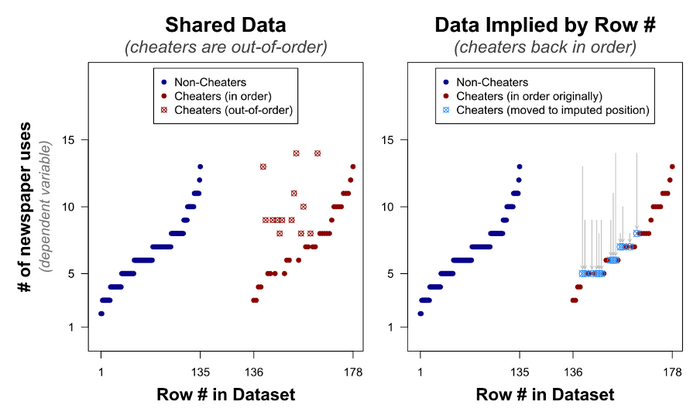
И переходим к пункту
3. Существенная связь между мошенничеством и творчеством исчезает, когда вы анализируете предположительно-реальные значения, а не выложенные Джино и соавтором. Значение p меняется от < ,0001 до ,292 (для предполагаемых минимальных значений) и p = ,180 (для предполагаемых максимальных).
То есть
Если бы значения не изменили вручную, никакой существенной разницы между мошенниками и немошенниками бы не было.
Далее будет более хардкорный анализ для интересующихся
Представим, что на самом деле нет никакой разницы между мошенниками и немошенниками в их способности придумать, как можно использовать газету.
При отсутствии фальсификации данных мы ожидаем не только, что среднее количество ответов будет одинаковым, но и что распределения целиком для обеих групп будут одинаковыми. Например, значение, которое находится на 20-м процентиле, должно быть одинаковым как для мошенников, так и для немошенников. И это также верно для 50-го процентиля, 80-го, 90-го и так далее.
Что ж, посмотрим на распределения обеих групп после фальсификации (слева) и предположительно-реальные (справа).

Тест Колмогорова-Смирнова для непараметрического сравнения целых распределений показывает p = ,456, что не позволяет отклонить гипотезу о том, что эти два распределения одинаковы (то есть они одинаковы).
Хорошо, но насколько впечатляет этот нулевой результат? Он принимается в качестве доказательства, что 13 наблюдений, «возвращенных к реальности» – на самом деле были сфальсифицированы.
Но, возможно, это неправда. Может быть, не имеет значения, какие 13 наблюдений вы измените? Что, если вы измените любые другие 13 наблюдений (из мошеннической группы) на ту же величину? Получим ли мы такие же похожие распределения и, например, такое же высокое значение p в тесте Колмогорова-Смирнова?
Краткий ответ: нет.
Data Colada провели несколько консервативных симуляций миллион раз. Каждый раз оценивалось сходство мошенников и немошенников с помощью теста Колмогорова-Смирнова и отслеживалось его p-значение.
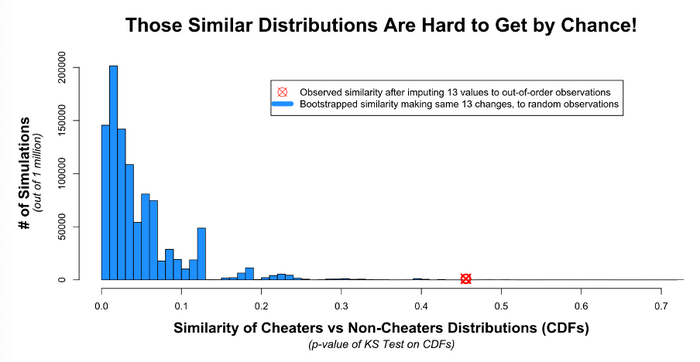
Посмотрите на красную точку, обозначающую p-значение после изменения тех самых 13 наблюдений. Нужно было быть чрезвычайно, невероятно удачливым, чтобы выбрать именно их и получить настолько похожие распределения по группам исключительно случайно.
То есть
Не существует (почти) никакого другого набора из 13 значений, которые вы могли бы изменить на ту же величину, чтобы получить два настолько похожих распределения. Этот результат довольно убедительно подтверждает, что сфальсифицированные ячейки и их исходные значения были определены правильно.
Комментарий Data Colada
«Мы считаем, что у Гарвардского университета есть доступ к файлу Qualtrics, который мог бы полностью подтвердить (или опровергнуть) наши опасения. Мы сообщили им, какой файл получить, какие ячейки проверить и какие значения они найдут в файле Qualtrics, если мы окажемся правы. Мы не знаем, сделали ли они это, и что они нашли, если сделали. Все, что мы знаем, это то, что 16 месяцев спустя они потребовали отозвать статью».
Спасибо, что прочитали.
Четвертая часть расследования пока не вышла, но ждем с нетерпением!
Показать полностью
6
Продолжение поста «Большой скандал в научном мире прямо сейчас»
К своему предыдущему посту увидела несколько похожих комментариев с вопросом: "Зачем вообще изучать такую ерунду?"

Вообще, любопытно, насколько иначе воспринимают научные исследования люди, не работающие в науке, – столько неожиданных вопросов и реакций!
А для тех, кому действительно интересно, попробую объяснить.
Штука в том, что наука, как и вся наша жизнь в обществе, очень разная, и то, что кажется полезным и классным одному, может быть совершенно бессмысленным для другого. Думаю, каждый легко придумает примеры, не хочу разводить отдельный срач.
Наука бывает прикладной и фундаментальной. Прикладная реже вызывает сомнения, зачем что-то исследуется, – чтобы применять, конечно! А вот фундаментальная наука постоянно сталкивается с вопросами от обывателей и даже ученых из других областей: «Нафига это вообще изучать и куда потом использовать?»
В то же время именно фундаментальная наука объясняет, как все устроено, а один и тот же принцип может затем использоваться в самых разных областях.
Конкретно по теме поста и претензиям «Кому вообще какое дело, где ставить подпись, что за проблема такая?»
Но ведь, если можно получать более честные ответы просто переставив место подписи, почему бы об этом не узнать и не воспользоваться в таких важных ситуациях, как свидетельские показания, разного рода экспертизы, финансовые документы и т.д.?
Кроме того, сама тема нечестного поведения при принятии решений, которую изучает Джино, Ариели и многие другие, очень важна. Например, полезно знать, сколько людей склонно обманывать в определенных ситуациях, какие это люди, почему они это делают, как этого избежать и много всего другого.
Надеюсь, стало немного понятнее!
Показать полностью

Ответ на пост «Большой скандал в научном мире прямо сейчас»
Грустно всё это. У меня мать работала до недавнего времени в одном институте и она практически единолично писала там все их научные статьи, а потом эти статьи распределяли на тех, кто сам не в состоянии написать, иначе потеря доплат от минобра в минусе и сотрудники, и институт. При этом реагентов для экспериментов постоянно нет, реагенты приходится докупать на свои деньги, образцы на свои и всё держится исключительно на неофициальных пожертвованиях от бизнеса. Но это ещё не всё, несколько раз она меня, как математика, просила провести анализ их данных, на мои резонные замечания, что с такой выборкой как у них(экспериментальных данных там было на 5-6 образцов, на большее нет финансирования) такие матанализы делать бессмысленно, отвечала что все у них в отрасли так делают и без этого руководство статьи не принимает. Но и это ещё не всё, уже сделанный анализ там ещё её начальница дорабатывала, чтобы графики красивше смотрелись, точно так же она и статьи её дорабатывала, при том, что начальница полный ноль в науке, но она начальник(с написанной за неё кандидатской диссертацией), ей видней. После того, как на внутреннюю кухню всей этой красоты посмотришь, рассказы из телевизора о наших невиданных прорывах в науке воспринимаются как какой-то весёлый стендап.
Видимо в гарвардской школе бизнеса такое же веселье происходит, а экономика это такая сфера, где мухлевать сам бог велел. Точных долгосрочных прогнозов никто не даёт, все их замечательные кривые спроса-предложения постоянно нарушаются, кризисы они предсказать не могут(или не хотят). Так что в конце концов, кому кому, как не профессору экономики понимать, что все эти их исследования довольно эфемерны, а 20 баксов это 20 баксов))
Большой скандал в научном мире прямо сейчас
В этом месяце академический мир был потрясен событием мирового масштаба: выяснилось, что очень известная женщина-ученый подделала данные в нескольких своих статьях.
Речь идет о Франческе Джино, профессоре Гарвардской школы бизнеса – одной из топовых и наиболее престижных школ бизнеса. Сама Джино имеет звание одного из 40 лучших профессоров бизнеса в возрасте до 40 лет и одного из 50 самых влиятельных мыслителей в области управления в мире. Ее академические показатели также очень высоки: например, индекс Хирша равен 87, и это ОЧЕНЬ много.
Что же произошло?
Группа исследователей Uri Simonsohn, Leif Nelson и Joe Simmons из Data Colada выпустила собственное расследование в 4 частях, из которых на сегодня вышло 3. Чтобы не перегружать пост, расскажу только про первую часть. Здесь и далее будет мой вольный пересказ их расследования, все картинки также будут оттуда.
Поехали.
Часть 1. Data Falsificada: "Clusterfake"
Название – отдельный лол, потому что это явно отсылка к слову «clusteruck» – бардак, пиздец, жопа и т.д.
Суть: два соавтора независимо подделали данные для двух разных исследований в статье о нечестном поведении.
Речь идет о статье, уже отозванной за фальсификацию данных в одном из приведенных в ней исследований. Теперь же выясняется, что данные были фальсифицированы еще в одном исследовании, причем независимо. Кстати, одним из соавторов и куратором статьи является другой известный ученый – Дэн Ариели, но сейчас речь не о нем.
Три исследования в этой статье якобы показывают, что люди с меньшей вероятностью будут обманывать, если подпишут обязательство отвечать честно в верхней части бланка согласия, а не в нижней.
Джино была единственным автором, участвовавшим в сборе и анализе данных, о которых пойдет речь.
Суть исследования была вот в чем. Участникам выдавался лист с 20 математическими головоломками, и за решение каждой из них они могли получить по 1 доллару. По прошествии 5 минут участников попросили сообщить экспериментатору, сколько головоломок они решили правильно, и затем выбросить свой лист с ответами. На деле участников вводили в заблуждение, что они могут без палева соврать, потому что каждый лист имел уникальный идентификатор. Таким образом, участники могли жульничать (и зарабатывать больше денег), думая, что никто не узнает, а исследователи могли вычислить, насколько сжульничал каждый участник.
Затем участники заполняли «налоговую» форму, в которой сообщали, сколько денег они заработали, а также сколько времени и денег они потратили, чтобы добраться до лаборатории – экспериментаторы частично компенсировали и эти затраты.
Гипотеза исследования была в том, влияет ли расположение подписи о декларации честности вверху или внизу формы (до или после заявленных расходов и числа решенных задач) на последующее поведение.

В итоге ученые показали очень сильный эффект: подпись сверху, по сравнению с подписью снизу, была связана с куда меньшей долей людей, завысивших свой результат, – соответственно 79 и 37%, а среднее число якобы решенных задач сверх реального было 0,77, по сравнению с 3,94. Ровно так же почти вдвое меньше была средняя сумма заявленных расходов на поездку до лаборатории (с 9,62 до 5,27 доллара).
Впечатляет, правда?
Но
Data Colada обнаружили серьезную аномалию в размещенных на открытом портале данных (привет, open science). В практически идеально отсортированных данных вдруг появляется 8 значений, которых там явно быть не должно:
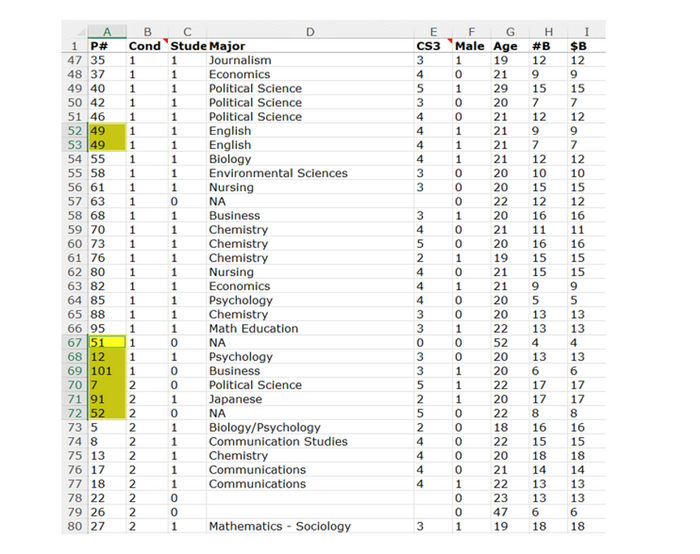
Продублированная запись участника №49 – это меньшая из проблем. Способа отсортировать данные таким образом, насколько известно, нет. Это означает, что выделенные строки либо перемещались вручную, либо менялся номер участника. И, судя по всему, верно первое.
Разумеется, подозрительные строки показывают огромный эффект. Все они являются одними из самых экстремальных наблюдений в своем условии, и все они в предсказанном направлении.
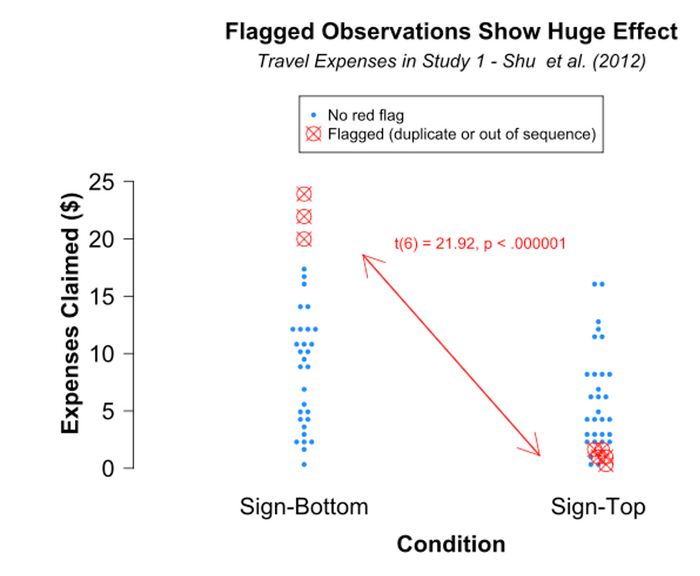
Коварный Excel
Данные для исследования были также опубликованы в виде файла Excel (.xlsx), который содержит формулы. С точки зрения «судебной экспертизы» данных это чрезвычайно ценно.
Малоизвестный факт о файлах Excel заключается в том, что они представляют собой буквально zip-файлы, пакеты файлов меньшего размера, которые Excel объединяет для создания единой электронной таблицы. Например, один файл в этом пакете содержит все числовые значения, которые появляются в электронной таблице, другой содержит все записи символов, третий — информацию о форматировании (например, шрифт Calibri или Cambria) и т.д.
Наиболее важным является файл с именем calcChain.xml. CalcChain сообщает Excel, в каком порядке выполнять вычисления в электронной таблице, примерно так: «Сначала решите формулу в ячейке A1, затем в ячейке A2, затем в B1 и т. д.». CalcChain — это сокращение от «цепочка вычислений».
CalcChain очень полезен в данном случае, потому что он может сообщить, была ли перемещена ячейка (или строка), содержащая формулу, и куда именно. То есть можно посмотреть, как эта электронная таблица выглядела в 2010 году до того, как она была изменена!
Авторы расследования приводят конкретный пример, как можно использовать calcChain: например, при перемещении формулы из ячейки С7 на место С12 информация об этом сохранится.
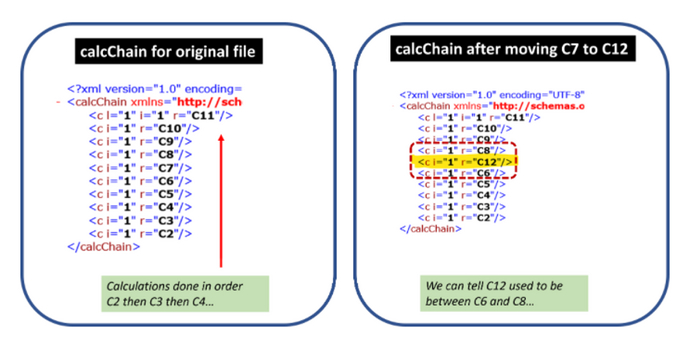
И вот что видно, когда смотришь calcChain по исследованию Джино:
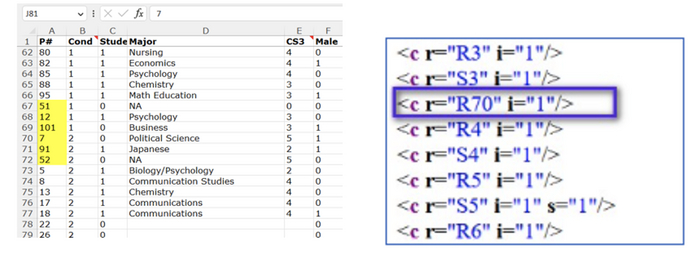
Строка №70 раньше была между рядами 3 и 4, а строки 3 и 4, очевидно, находятся в верхней части электронной таблицы. И, поскольку электронная таблица отсортирована по столбцу B, эти строки относятся к контрольному условию 0, а совсем не 1 и 2, где они в итоге оказались.
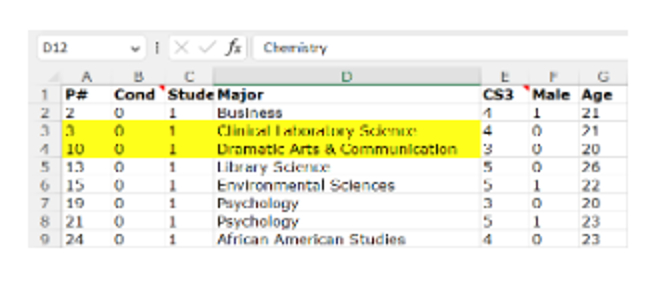
Кроме того строки 3 и 4 имеют ID участников №3 и №10. Напомню, что строка 70 имеет ID №7, поэтому до того, как ее переместили вручную, она находилась точно в ожидаемой позиции (между 3 и 10), если 1) это наблюдение изначально было в состоянии 0, и 2) электронная таблица была отсортирована по условию и идентификатору, как есть. Все это убедительно свидетельствует о том, что строка 70 была перемещена из контрольного условия (условие 0) в условие подписи снизу (условие 2).
Вот такая совершенно топорная фальсификация данных.
Мой комментарий
Я работаю в науке, и от себя добавлю, что, к сожалению, «чистота» исследований во многом зависит от добросовестности самого ученого и его научной группы. Иногда ошибки делаются по невнимательности или незнанию правил сбора данных и/или статистической обработки. А иногда – как в этом случае – намеренно, ради красивого эффекта.
Проверить данные тоже возможно далеко не всегда из-за того, что часто их вовсе не публикуют или обещают прислать по запросу (на который потом часто никто не отвечает). Ну и разобраться в чужом огромном датасете, не зная, как он устроен и насколько аккуратно собирался – задача сложная.
Грустно, что в науке, по сути, нет «академической полиции», которая бы как-то наказывала за такие проступки. Максимум – это увольнение/непродление контракта, после чего такие ученые просто идут работать в другие университеты, которым не так важна репутация сотрудников. В случае Джино сейчас – это «administrative leave» – отстранение от работы с сохранением зарплаты и прочих плюшек.
P.S. Если тема интересна, могу сделать посты по второй и третьей частям расследования, а также с нетерпением ждем четвертую!
Показать полностью
6

Пятёрочка и сосиски...
Много нелестных отзывов про эту сеть. Добавлю от себя....
Место действия: Москва, проезд Якушкина 10.
Обычно найденную просрочку отдавал сотруднику магазина но тут что-то меня остановило. Две коробки сосисок с очень привлекательной ценой. Обычно такие не беру, но решил глянуть состав. И увидел пачку просроченную почти на 3 недели! Редкий улов!

Взял соседнюю, потом ещё одну, порылся - на всех другая маркировка, разительно отличающаяся от заводской...

Причём по упаковкам видно, что явно не вчера их привезли. Взял оригинал и выловил администратора зала. Диалог получился очень интересный.
Жаль не стал записывать дальше. Когда отошёл она стала причитать директору что мужик нашел просрочку и перемаркер и будет жаловаться. А чуть позже, пробегая мимо с охранником показала на меня рукой и попросила отследить по камерам... А вдруг это я злодей и такое им сотворил! 🤣
Я конечно не эксперт в маркировке, но смутные догадки подсказывают мне, что я был прав. Да и паника у администратора была нешуточная.
Соседние сардельки и другая продукция этого производителя оказались с нормальной маркировкой где указан срок, состав и другие данные.
Не знаю есть ли тут представители Роспотребнадзора и завода изготовителя - в любом случае завтра им напишу.
А всем рекомендую очень внимательно в Пятёрочках изучать маркировку продукции, особенно скоропортящихся товаров.
Update
Вечером, через Ватсапп сделал обращение на завод, но на объективность ответа не сильно надеюсь - судя по логотипу в чате это тоже Пятёрочка... Обещались принеприменно дать ответ до 15 января.

Показать полностью
3
1
Как подготовить машину к долгой поездке
Взять с собой побольше вкусняшек, запасное колесо и знак аварийной остановки. А что сделать еще — посмотрите в нашем чек-листе. Бонусом — маршруты для отдыха, которые можно проехать даже в плохую погоду.