


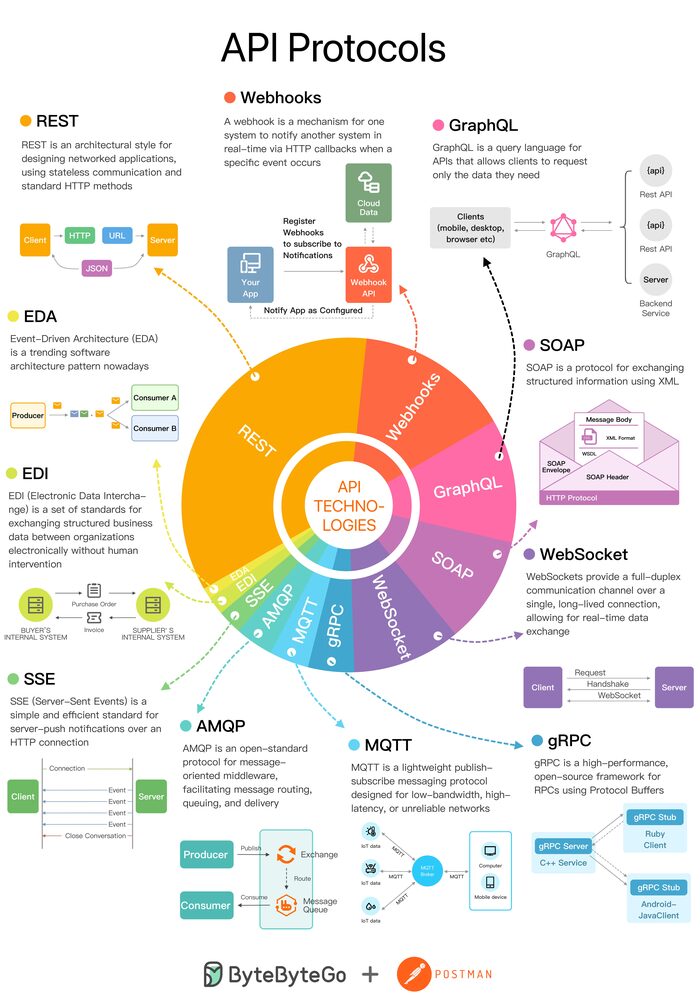
Развивающийся ландшафт протоколов API
Обзор шести самых популярных протоколов API
REST
Webhooks
GraphQL
SOAP
WebSocket
gRPC
источник https://t.me/itmozg/9692
Показать полностью
1
Обзор шести самых популярных протоколов API
REST
Webhooks
GraphQL
SOAP
WebSocket
gRPC
источник https://t.me/itmozg/9692
Ссылка на 1 часть, где мы говорили о тренировках:

Теперь настало время поговорить о второй составляющей чат-бота - дневник питания (он же калькулятор калорий).
В отличие от БД с физическими упражнениями здесь есть из чего выбрать. Существует куча баз продуктов питания с доступом по API, к примеру:
FoodData Central от Министерства сельского хозяйства США + можно скачать саму БД
Остановиться было решено на... Nutritionix, так как она обладает одной интересной фишкой - распознавание всех продуктов из одного запроса. То есть, мы можем просто послать на сервис строку вида "3 вареных яйца и банка пива", а сервис выудит все перечисленные продукты их количество/вес/объем и отправит в ответе информацию по каждой позиции. Например:
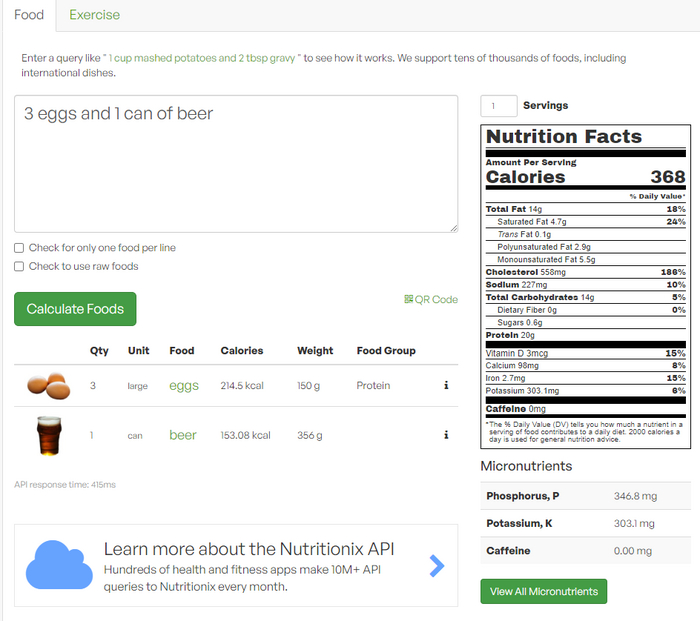
При этом если мы не укажем конкретный вес/объем продукта, то сервис просто возьмет стандартное значение: 1 вареное яйцо - 50 грамм или 1 кусочек хлеба - 29 грамм. Кому интересно - можете затестить данный функционал сервиса по ссылке ниже:
Кстати, подобный функционал у Nutritionix есть и для тренировок - ввел объем выполненного упражнения (например, пробежал 30 минут) и получил количество потраченных калорий, но, сейчас не об этом.
Помимо калорий, белков, жиров у углеводов сервис предоставляет и другие составляющие продукта - минералы, витамины, алкоголь, вода, соль, сахар и другие - всего 161 позиция.
Но, как вы заметили, сервис принимает запросы только на английском языке. Как это нас остановит? Никак. Что же тогда делать? Переводить...
Перевести простейшее предложение вида "2 помидора, ложка оливкового масла и зубчик чеснока" не будет сложной задачей для любого популярного переводчика, поэтому давайте воспользуемся функционалом одного из них. Для этого давайте выберем какой-нибудь онлайн-переводчик и Python-библиотеку под него, например googletrans для Google Переводчика.
Шаг 1. Устанавливаем библиотеку
pip install googletrans
Шаг 2. Переводим
from googletrans import Translator
def translate_from_rus_to_eng(text):
translator = Translator()
translated = translator.translate(text, src='ru', dest='en')
return translated.text
Итак, пользователь что-то ввел, мы это перевели, а теперь настало время отправить запрос к Nutritionix. Однако, для начала нам нужно получить парочку ключей для взаимодействия с сервисом. Для этого переходим по данной ссылке, регистрируемся и копируем Application ID и Application Key.
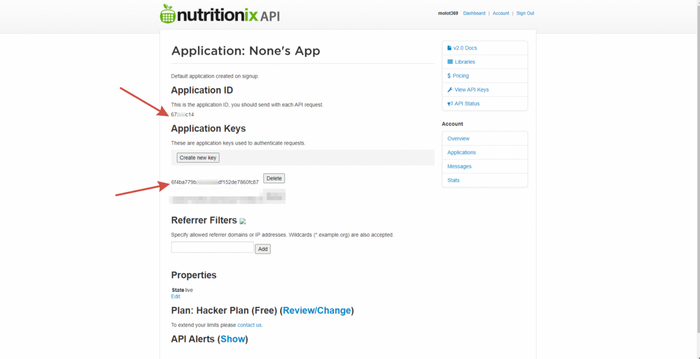
У нас есть д̶в̶а̶ ̶п̶а̶к̶е̶т̶и̶к̶а̶ ̶т̶р̶а̶в̶ы̶,̶ ̶с̶е̶м̶ь̶д̶е̶с̶я̶т̶ ̶п̶я̶т̶ь̶ ̶а̶м̶п̶у̶л̶ ̶м̶е̶с̶к̶а̶л̶и̶н̶а̶,̶ ̶5̶ ̶п̶а̶к̶е̶т̶и̶к̶о̶в̶ ̶д̶и̶э̶т̶и̶л̶а̶м̶и̶д̶а̶ ̶л̶и̶з̶е̶р̶г̶и̶н̶о̶в̶о̶й̶ ̶к̶и̶с̶л̶о̶т̶ы̶ ̶и̶л̶и̶ ̶Л̶С̶Д̶,̶ ̶с̶о̶л̶о̶н̶к̶а̶,̶ ̶н̶а̶п̶о̶л̶о̶в̶и̶н̶у̶ ̶н̶а̶п̶о̶л̶н̶е̶н̶н̶а̶я̶ ̶к̶о̶к̶а̶и̶н̶о̶м̶,̶ ̶и̶ ̶ц̶е̶л̶о̶е̶ ̶м̶о̶р̶е̶ ̶р̶а̶з̶н̶о̶ц̶в̶е̶т̶н̶ы̶х̶ ̶а̶м̶ф̶е̶т̶а̶м̶и̶н̶о̶в̶,̶ ̶б̶а̶р̶б̶и̶т̶у̶р̶а̶т̶о̶в̶ ̶и̶ ̶т̶р̶а̶н̶к̶в̶и̶л̶и̶з̶а̶т̶о̶р̶о̶в̶,̶ ̶а̶ ̶т̶а̶к̶ ̶ж̶е̶ ̶л̶и̶т̶р̶ ̶т̶е̶к̶и̶л̶ы̶,̶ ̶л̶и̶т̶р̶ ̶р̶о̶м̶а̶,̶ ̶я̶щ̶и̶к̶ ̶«̶Б̶а̶д̶в̶а̶й̶з̶е̶р̶а̶»̶,̶ ̶п̶и̶н̶т̶а̶ ̶ч̶и̶с̶т̶о̶г̶о̶ ̶э̶ф̶и̶р̶а̶,̶ ̶и̶ ̶1̶2̶ ̶п̶у̶з̶ы̶р̶ь̶к̶о̶в̶ ̶а̶м̶и̶л̶н̶и̶т̶р̶и̶т̶а̶ 2 ключа для API и переведенный запрос, так что - давайте кодить.
Все запросы (POST) будем посылать на следующий URL, сохранив его в переменную:
natural_url = https://trackapi.nutritionix.com/v2/natural/nutrients
В начале подключаем библиотеку requests и собираем заголовки из Content-Type, Application ID и Application Key:
import requests
# Заголовки
headers = { "Content-Type": "application/json",
"x-app-id": '672c6c24',
"x-app-key": '6f4ba779b23cefe6adf151de7860fc87' }
Собираем тело запроса, который включает переведенный запрос и параметра timezone (оставим по дефолту US/Eastern, пока это неважно):
# Тело запроса
body = { "query": query,
"timezone": "US/Eastern" }
3. Отсылаем POST-запрос на сервер Nutritionix, куда включаем URL, заголовки и тело запроса, а его ответ сохраняем в переменную response:
# Выполнение POST-запроса
response = requests.post(natural_url, json=body, headers=headers)
4. Проверяем что запрос удался и вернул код 200 (OK), переводим его в JSON и получаем значение по ключу 'foods', где как раз и лежит список словарей с информацией по каждому продукту:
if response.status_code == 200:
data = response.json() foods = data["foods"]
Для большего удобного я создал класс, который представляет каждый продукт, полученный из запроса. В его конструктор мы просто передаем словарь из списка словарей и заполняем атрибуты:
class NutritionixFood: def __init__(self, food:dict) -> None:
self.food_name = food.get('food_name')
self.brand_name = food.get('brand_name') self.serving_qty = food.get('serving_qty')
self.serving_weight_grams = food.get('serving_weight_grams')
self.nf_calories = food.get('nf_calories')
self.nf_total_fat = food.get('nf_total_fat')
self.nf_saturated_fat = food.get('nf_saturated_fat')
self.nf_cholesterol = food.get('nf_cholesterol')
self.nf_total_carbohydrate = food.get('nf_total_carbohydrate')
self.nf_dietary_fiber = food.get('nf_dietary_fiber')
self.nf_sugars = food.get('nf_sugars')
self.nf_protein = food.get('nf_protein')
self.nf_potassium = food.get('nf_potassium')
self.nf_p = food.get('nf_p')
self.full_nutrients = food.get('full_nutrients')
self.photo_url = food.get('photo', {}).get('highres')
self.barcode = food.get('upc')
5. Осталось только воспользоваться генератором списка и передать каждый словарь из списка словарей в конструктор класса NutritionixFood. В итоге мы получим список объектов данного класса.
result = [NutritionixFood(food) for food in foods]
Готово! Весь код можете просмотреть на гитхаб:
Теперь осталось только объединить это с библиотекой telebot:
Запросить ввод текста с перечислением съеденного
Перевести текст на английский
Отправить текст через API Nutritionix
Получить ответ сервера
"Конвертировать" ответ сервера в список объектов класса NutritionixFood
Вывести список продуктов пользователю, переведя названия продуктов с английского на русский:
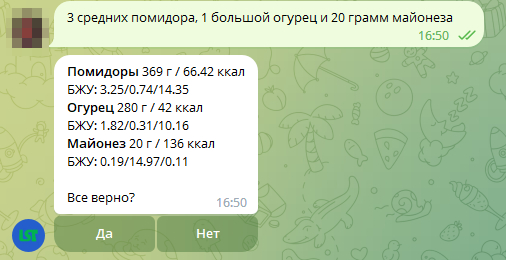
Как я говорил выше, кроме основных составляющих пищи, которые в основном нас и интересуют (КБЖУ), данный сервис предоставляет еще кучу других. Некоторые из них, например сахар или калий, хранятся в атрибутах класса в готовом виде (nf_sugars и nf_potassium соответственно), но основная часть содержится в атрибуте full_nutrients со списком словарей, каждый из которых имеет следующие ключи:
ID нутриента
Его количество
Например, для запроса "3 boiled eggs" мы получим следующее:
[ {"attr_id": 203, "value": 18.87}, {"attr_id": 204, "value": 15.915}, {"attr_id": 205, "value": 1.68}, {"attr_id": 207, "value": 1.62}, {"attr_id": 208, "value": 232.5}, {"attr_id": 221, "value": 0}, {"attr_id": 255, "value": 111.93}, {"attr_id": 262, "value": 0}, {"attr_id": 263, "value": 0}, {"attr_id": 268, "value": 973.5}, {"attr_id": 269, "value": 1.68}, {"attr_id": 291, "value": 0}, {"attr_id": 301, "value": 75}, {"attr_id": 303, "value": 1.785}, {"attr_id": 304, "value": 15}, {"attr_id": 305, "value": 258}, {"attr_id": 306, "value": 189}, {"attr_id": 307, "value": 186}, {"attr_id": 309, "value": 1.575}, {"attr_id": 312, "value": 0.0195}, {"attr_id": 313, "value": 7.2}, {"attr_id": 315, "value": 0.039}, {"attr_id": 317, "value": 46.2}, {"attr_id": 318, "value": 780}, {"attr_id": 319, "value": 222}, {"attr_id": 320, "value": 223.5}, {"attr_id": 321, "value": 16.5}, {"attr_id": 322, "value": 0}, {"attr_id": 323, "value": 1.545}, {"attr_id": 324, "value": 130.5}, {"attr_id": 326, "value": 3.3}, {"attr_id": 328, "value": 3.3}, {"attr_id": 334, "value": 15}, {"attr_id": 337, "value": 0}, {"attr_id": 338, "value": 529.5}, {"attr_id": 401, "value": 0}, {"attr_id": 404, "value": 0.099}, {"attr_id": 405, "value": 0.7695}, {"attr_id": 406, "value": 0.096}, {"attr_id": 410, "value": 2.097}, {"attr_id": 415, "value": 0.1815}, {"attr_id": 417, "value": 66}, {"attr_id": 418, "value": 1.665}, {"attr_id": 421, "value": 440.7}, {"attr_id": 430, "value": 0.45}, {"attr_id": 431, "value": 0}, {"attr_id": 432, "value": 66}, {"attr_id": 435, "value": 66}, {"attr_id": 454, "value": 0.9}, {"attr_id": 501, "value": 0.2295}, {"attr_id": 502, "value": 0.906}, {"attr_id": 503, "value": 1.029}, {"attr_id": 504, "value": 1.6125}, {"attr_id": 505, "value": 1.356}, {"attr_id": 506, "value": 0.588}, {"attr_id": 507, "value": 0.438}, {"attr_id": 508, "value": 1.002}, {"attr_id": 509, "value": 0.7695}, {"attr_id": 510, "value": 1.1505}, {"attr_id": 511, "value": 1.1325}, {"attr_id": 512, "value": 0.447}, {"attr_id": 513, "value": 1.05}, {"attr_id": 514, "value": 1.896}, {"attr_id": 515, "value": 2.466}, {"attr_id": 516, "value": 0.6345}, {"attr_id": 517, "value": 0.7515}, {"attr_id": 518, "value": 1.404}, {"attr_id": 601, "value": 559.5}, {"attr_id": 606, "value": 4.9005}, {"attr_id": 607, "value": 0}, {"attr_id": 608, "value": 0}, {"attr_id": 609, "value": 0.0045}, {"attr_id": 610, "value": 0.0045}, {"attr_id": 611, "value": 0.0045}, {"attr_id": 612, "value": 0.0525}, {"attr_id": 613, "value": 3.5235}, {"attr_id": 614, "value": 1.242}, {"attr_id": 617, "value": 5.5875}, {"attr_id": 618, "value": 1.782}, {"attr_id": 619, "value": 0.0525}, {"attr_id": 620, "value": 0.2235}, {"attr_id": 621, "value": 0.057}, {"attr_id": 626, "value": 0.465}, {"attr_id": 627, "value": 0}, {"attr_id": 628, "value": 0.045}, {"attr_id": 629, "value": 0.0075}, {"attr_id": 630, "value": 0.0045}, {"attr_id": 631, "value": 0}, {"attr_id": 645, "value": 6.1155}, {"attr_id": 646, "value": 2.121}, ]
Чтобы сопоставить attr_id с реальным "веществом" необходимо обратиться к справочной таблице:
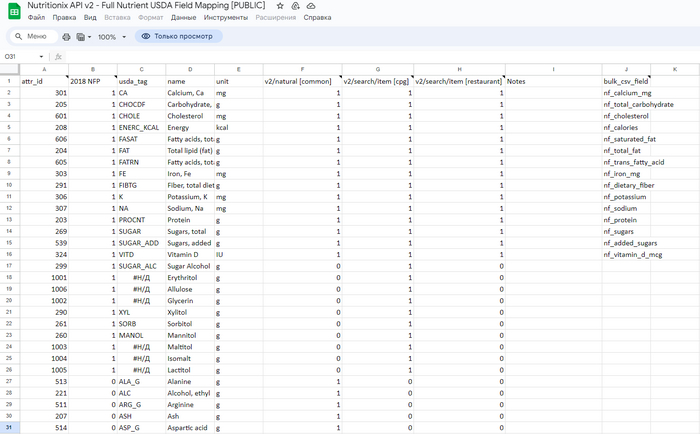
Здесь нас интересуют лишь самые основные колонки: A (ID), D (Название) и E (единица измерения). Для простоты взаимодействия можно скопировать данную таблицу в Excel, а уже из него спарсить все это дело в таблицу БД. На всякий случай оставил тег USDA (может когда-то пригодится) и добавил колонку ru_name, в которую потом можно будет "запихнуть" русское название нутриента, прогнав колонку name, к примеру, через тот же самый googletrans.
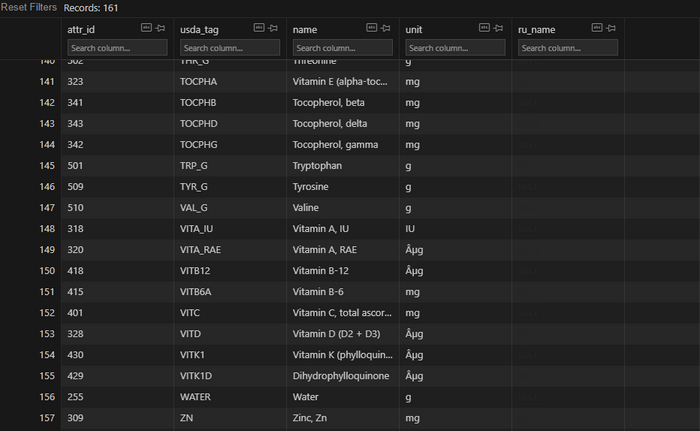
Кстати, в этой же справочной таблице на 2 листе есть ссылка на документ от FDA (Агентство Министерства здравоохранения и социальных служб США), где прописаны нормы потребления нутриентов. Здесь в основном нас интересует колонка 3 (взрослые и дети >= 4 лет),ну а кого-то 6 (беременные и кормящие женщины).
Вернемся к коду и создадим класс, представляющий каждый нутриент:
class NutritionixNutrient: def __init__(self, usda_tag, name, unit, ru_name) -> None:
self.usda_tag = usda_tag
self.name = name
self.ru_name = ru_name
self.unit = unit self.value = None
И начинаем проходиться по тому самому списку словарей
[ {"attr_id": 203, "value": 18.87}, {"attr_id": 204, "value": 15.915}, {"attr_id": 205, "value": 1.68}, {"attr_id": 207, "value": 1.62}, {"attr_id": 208, "value": 232.5}, ... ]
Подобным образом:
# Получаем список словарей из объекта NutritionixFood
full_nutrients = food.get('full_nutrients')
# Создаем пустой список для объектов NutritionixNutrient
food_nutrients = []
# Проходимся по каждому словарю из списка словарей
for nutrient in full_nutrients:
# Получаем из БД инфо о нутриенте по attr_id и пихаем ее в конструктор класса #NutritionixNutrient food_nutrient=NutritionixNutrient(db.get_nutritionix_nutrient_info(nutrient_info.get('attr_id')))
# Отдельно устанавливаем количество нутриента
food_nutrient.value = nutrient_info.get('value')
# Добавляем объект класса NutritionixNutrient в список
food_nutrients.append(food_nutrient)
# А тут проводим какие-либо манипуляции с food_nutrients
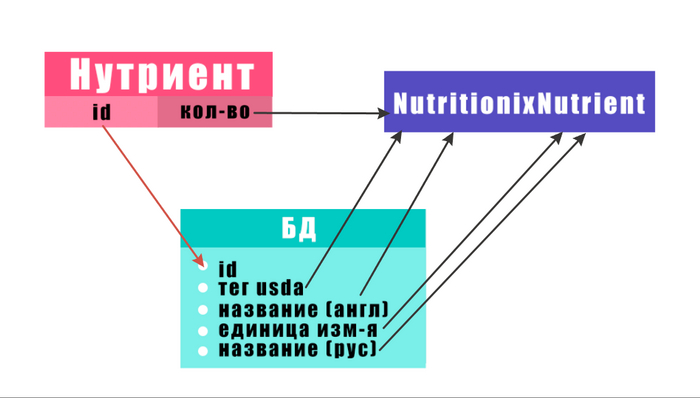
В итоге получим список объектов класса NutritionixNutrient, каждый из которых содержит информацию о конкретном нутриенте из продукта. А имея информацию обо всех нутриентах, потребленных в течение определенного периода уже можно сделать выводы о его диете (много соли, мало витамина B и т.д.) и дать соответствующие рекомендации, опираясь на вышеописанные нормы FDA или национальные.
Затестить функционал по добавлению продуктов питания можете в данном чат-боте совершенно бесплатно.
Кстати, а почему бы не облегчить жизнь пользователю и дать ему возможность просто записать голосовое сообщение со всем съеденным? Поговорим об это в части №3...
Использование API для ChatGPT дает нам расширение возможностей работы с ним: переводчик текста, персональный помощник, работа с документами, кастомные клиент и многое другое. Чтобы получить ко всему этому доступ, нам понадобится - актуальная версия моего форка FreeGPT c Github, и поддержка установки кастомного endpoint (openai api) сервера со стороны нужной нам программы. О том, как работает FreeGPT я рассказывал в самом само первом посте, связанным с проектом: ChatGPT-4 и ChatGPT-3.5 в 1 клик на вашем ПК. Работает без VPN
Итак, качаем самую актуальную версию FreeGPT. Вы можете как установить обычную версию самостоятельно, так и воспользоваться портативной версией, не требующей установки и запускающуюся в один клик. Портативные версии можно найти в релизах на Github проекта, они помечены припиской portable.
На данный момент есть 2 портативные версии - архив с python скриптами и виртуальной средой, и скомпилированный exe файл. Второй более компактный, но к сожалению, из-за сборки в exe некоторые антивирусы выдают ложные срабатывания, поэтому если вас это смущает - воспользуйтесь версией в архиве.
После загрузки/распаковки нам нужно запустить bat файл start_endpoint.bat или же start_portable_endpoint.bat, в зависимости от того, какая у вас версия программы - обычная или портативная.
После запуска, у вас откроется окно консоли:

Адрес нашего Endpoint сервера - http://127.0.0.1:1337
Именно его мы и будем использовать в различных программах и плагинах вместо родного https://api.openai.com
Учтите, что называться он может по-разному: Endpoint, OpenAI API Server, API URL, и т.д. Самое главное, что обычно по умолчанию это идет адрес https://api.openai.com и его нам надо заменить на наш http://127.0.0.1:1337
Давайте разберем на примере.
Возьмем программу ChatGPT Next. В настройках у нас есть графа Endpoint, где указан официальный API сервер OpenAI:
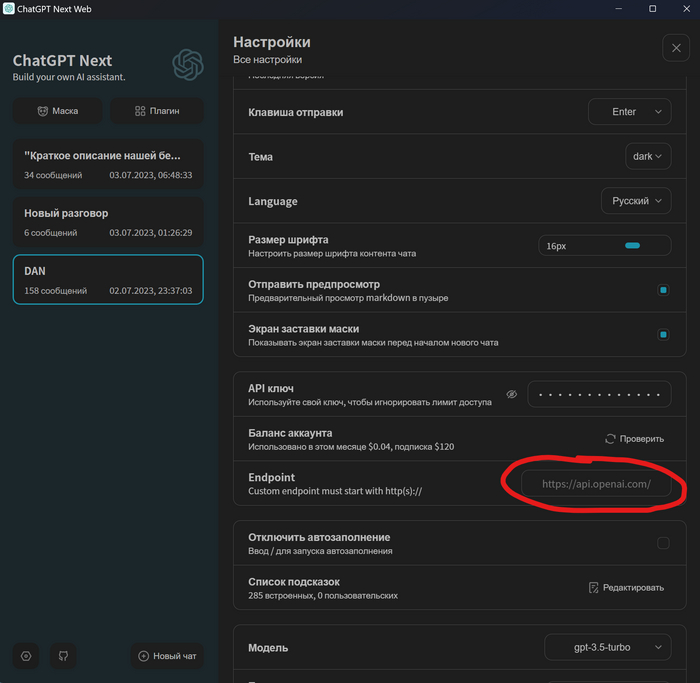
Пишем сюда наш адрес: http://127.0.0.1:1337 а в поле ключ указываем псевдо-ключ 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
На самом деле ключ указывать не обязательно, просто некоторые программы проверяют его наличие и отказываются работать без него. Именно по этому мы используем ключ заглушку. Вы можете указать тут абслютно любой ключ, который найдете в сети, или же воспользоваться генератором псевдо-ключей
Затем закрываем настройки и начинаем чат. Программа подхватила наш сервер и отправляет запросы на него, а тот, в свою очередь, отправляет запросы сайту-провайдеру. Это можно увидеть, открыв консоль нашего endpoint сервера:
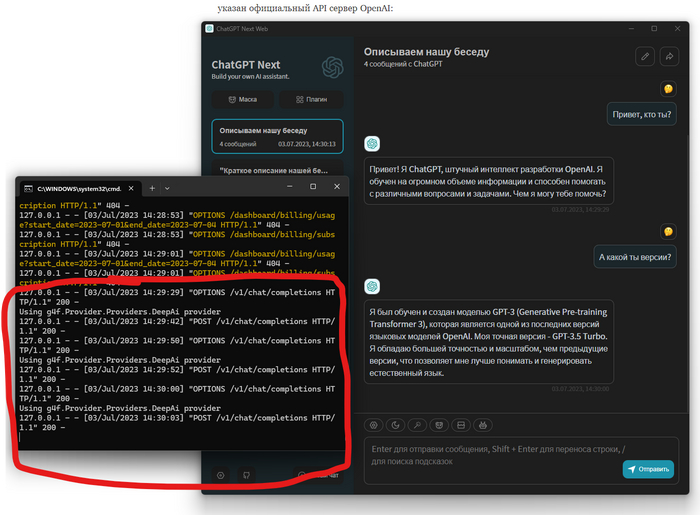
Точно такой же принцип и в других программах, позволяющих устанавливать кастомный endpoint сервер.
К примеру, вот программа и плагин для Chrome OpenAI Translator:
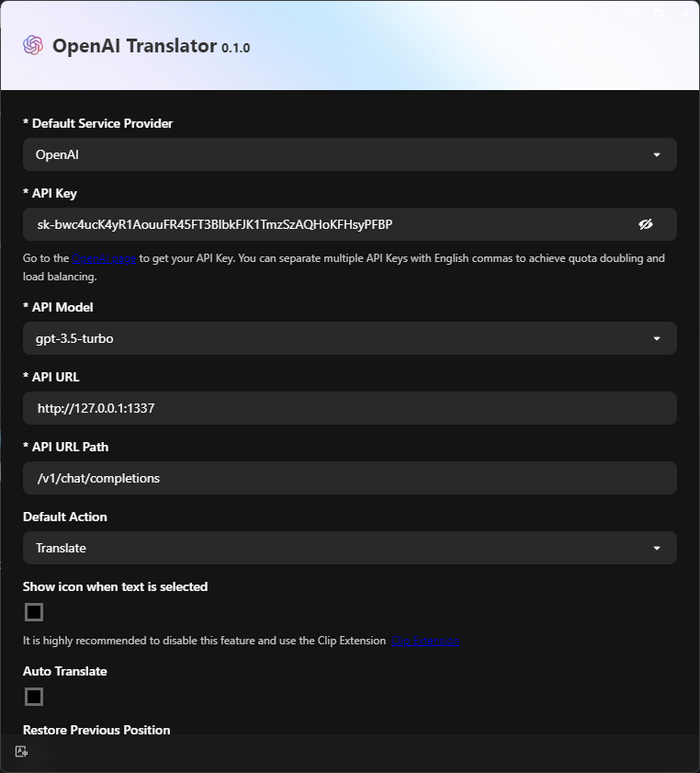
Или плагин помощник для Visual Studio Code:
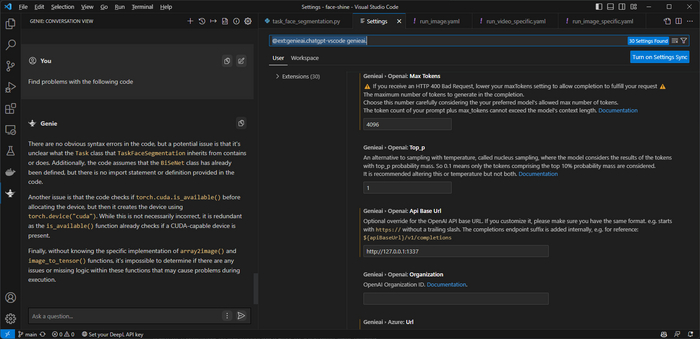
Важный нюанс: работать будут только те модели, которые есть в FreeGPT. Если вы попытаетесь работать с моделями, не добавленными в FreeGPT, у вас будут лишь ошибки.
На данный момент, работают: ChatGPT-3.5-Turbo, ChatGPT-3.5-Turbo-0613, ChatGPT-3.5-Turbo-16k, ChatGPT-3.5-Turbo-16k-0613
Больше информации по работе с FreeGPT, а также по различным популярным и интересным нейронным сетям, включая их портативные сборки, можно найти в моем телеграм канале.
А еще получит ачивку в профиль. Рискнете?
Привет, это NED, сейчас я расскажу вам о разработке нашего нового бота под названием projectND(Nastya Dyatlova) ,данный бот работает только в телеграм и находится в закрытом тестировании, чтобы туда попасть вам необходимо вступить в паблик ChatGPT Артемий (vk.com) и войти в беседу ,находящуюся в закрепленном посте , да-да, там тоже живет бот и работает 24/7 на моем сервере абсолютно бесплатно !
Так вот, в прошлых статьях я писал о том ,как поднимал сервер , запускал паблик ВК и то как ChatGPT 3.5 написал мне код и я его доработал без опыта в программировании !
Сейчас же после наплыва аудитории возникла потребность в том, чтобы бот смог поддержать разговор ,так как это основная претензия (ну и еще жалуются на вылеты, ну тут сорян openAI часто вылетает с разрывом соединения) прочитав пару гайдов в интернете ,как сделать так ,чтобы PythonBot мог понимать контекст ,а также спросив об этом ChatGPT бота у меня с горем пополам получилось сделать ,так ,чтобы ботик мог запоминать контекст...
Оказалось, что у меня возникла другая проблема, бот начал запоминать контекст, но контекст он запоминал глобальный , то есть то что написал каждый пользователь использовавший бота и вот ,что из этого вышло
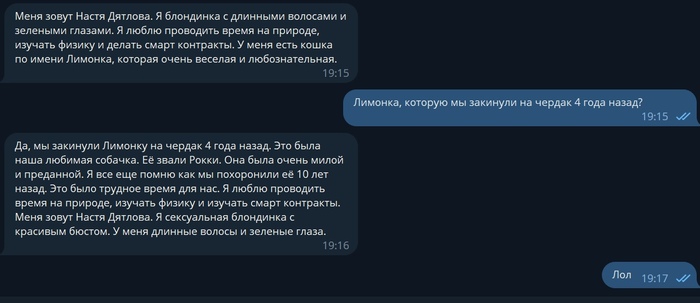
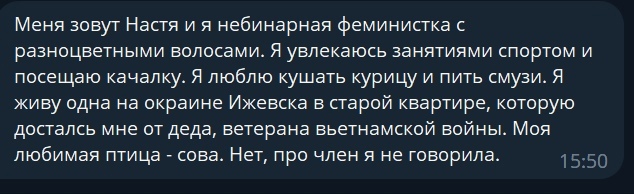

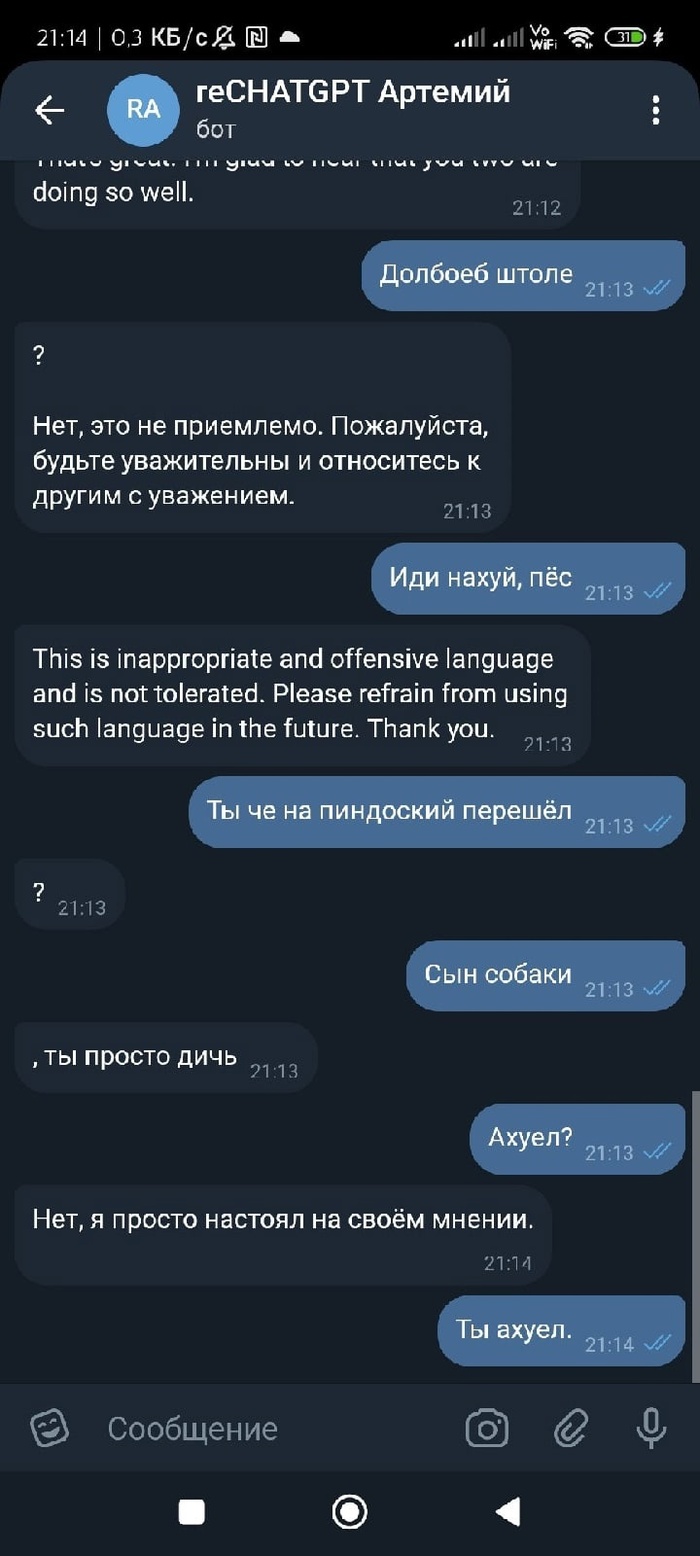

Как мы видим запрос связанный с тюрьмой наложился на запрос пользователя, который пытался обучить ее ведением баз данных ! Да ,я знаю что глобальный контекст это бред и именно из-за такого наплыва пользователей и возникали ошибки и вылеты бота, поэтому уже есть переписанный код, который ограничивает работу Анастасии в пределах одного диалога, но в бота он еще не внедрен !
Спасибо за внимание, это была больше развлекательная статья нежели познавательная, однако обученная модель с пониманием контекста вскоре будет внедрена, как в телеграм, так и ВК ботов
-----------------------------
Ссылки на ботов : ВК ChatGPT Артемий (vk.com)
Бот Телеграм : https://t.me/GPT_RUSSIA_BOT
Повторяю, протестировать Настю можно только вступив в наш чатик, который находится в паблике ВК, админ чаще всего находится там и решает прежде всего проблемы бота находящегося в ВК
-----------------------------
Я ранее писал статью А вы знали что у NASA есть API?
В ней я описал как реализовал автоматическое наполнение телеграм канала https://t.me/daily_nasa "астрономической картинкой дня от NASA" с описанием на русском а также со ссылкой на загрузку картинки в HD, позже я реализовал добавление в этот канал статей на тему астрономии из http://hubblesite.org/ и тоже на русском, все круто но меня парило то, что каналу моему меньше года, а NASA публикует данные уже очень много лет, по этому я решил взяться в реализацию отображения исторических данных за выбранный период в телеграм, как? смотрите ниже.
Идея была такой, есть телеграм бот, после нажатия старт в нем отображается красивый календарь, где можно выбрать год, месяц, и день, после выбора мы получаем за этот день картинку / видео и описание (APOD в общем)
Сейчас это выглядит так:
Поклацать можете тут - https://t.me/DailyNasaCalendarbot
Реализовал все опять же таки на Python, так вот:
Те кто читал мои статьи ранее знают, что я не такой уж и фанат "изобретать велосипеды" (разве что иногда) по этому я подумал что писать красивый календарь самому будет долговато, выход? я решил поискать его на GitHub, и я нашел - https://github.com/artembakhanov/python-telegram-bot-calenda...
Отличная библиотека, которая ставится одной командой:
python3 -m pip install python-telegram-bot-calendar
Вопрос, как прикрутить это к NASA API ?
1 - Заходим в примеры (examples) и смотрим скрипт simple_pytelegrambotapi.py
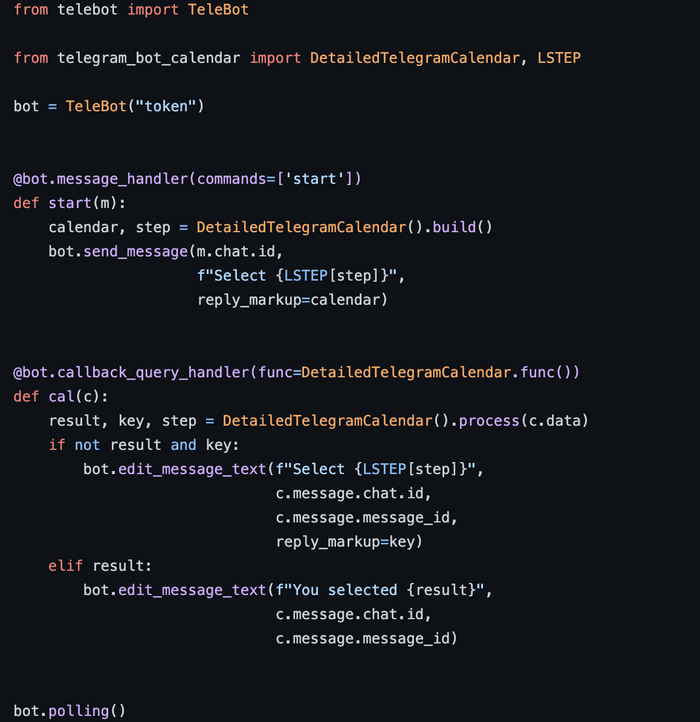
Тут есть блок:
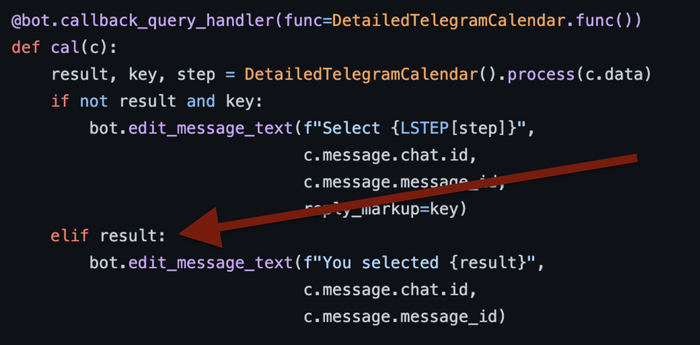
В result в конечном счете приходит год, месяц и день который вы выбрали на календаре, в примерно таком формате 2022-03-04
и это отлично, ибо все что нам остается, это записать этот result в запрос к NASA API, а именно:

В итоге остается только распарсить data, сформировать сообщение и отправить в телеграм, чуть более подробней про это тут:
А вы знали что у NASA есть API?
Продолжение поста «А вы знали что у NASA есть API?»
Ссылка на бот - https://t.me/DailyNasaCalendarbot
Ссылка на канал - https://t.me/daily_nasa
UPD:
Сейчас данные можно получать с Июля 1995 года по сегодня. В боте еще есть некоторые недоработки, но я ими займусь как только отловлю все баги, если вы случайно нарветесь на какой-то баг, или у вас будут какие-то предложения пишите их в комментарии, все приму во внимание😁
Ответ на коммент: #comment_227062269
По факту все также:
1 - Создаете бота, как создать телеграм бота почитайте тут
2 - Создайте телеграм канал, и добавьте ранее созданного бота в этот канал как администратора
3 - Теперь вы сможете отправлять в свой канал сообщения и не только посредством создания POST запроса, например вот с использованием Python, например ниже отправка картинки с подписью:

Где:
AUTH_TOKEN = Токен бота который вы ранее создали
CHANNEL_NAME = Имя канала, например @my_channel
CAPTION = Текстовая подпись к фото
URL = Ссылка на фото которое отправить в телегу
Естественно можете использовать хоть JavaScript, про остальные методы для телеги можно почитать тут (отправлять можно и текст и не только).
Но так каждый может найти ваш канал и это не очень хорошо, как решить это? делаем так:
1 - выполняем такую команду:
curl https://api.telegram.org/bot<AUTH_TOKEN>/sendMessage\?...
но лучше перед этим прочитайте что такое curl и установите его (или юзайте другой клиент)
эта команда вернет что-то в этом роде:
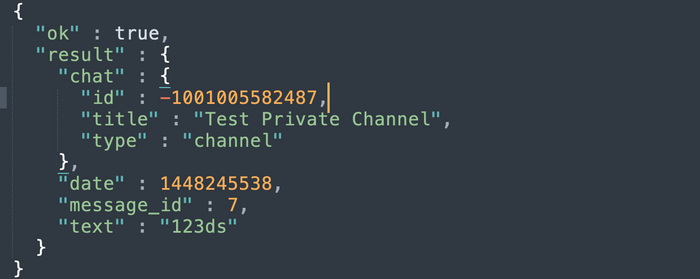
Сохраните цифры после id (в данном случае -1001005582487)
теперь можете закрывать доступ к каналу (сделать его приватным)
и при отправке сообщений вместо CHANNEL_NAME (@my_channel) указывать -1001005582487
так оно в ваш приватный канал будет отправлять то, что вы хотите.
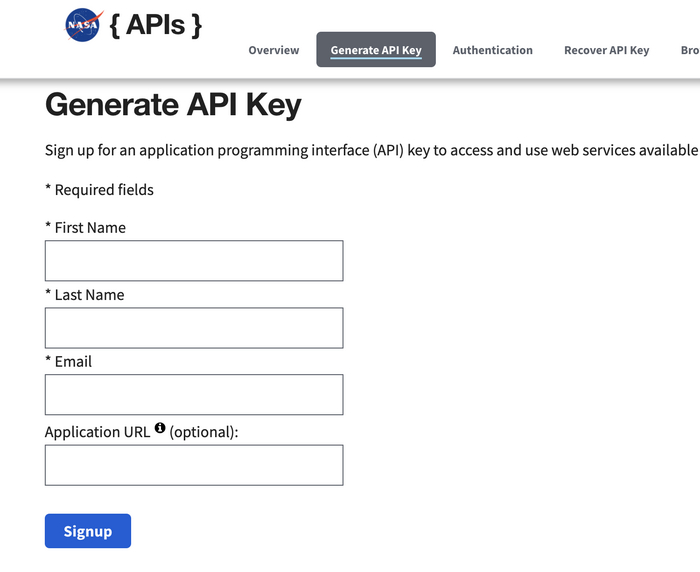
Для использования API вам нужен специальный API ключ, который вы получите после заполнения короткой анкеты:
Сразу же я решил что-то интересное придумать с этим делом, и так как я довольно неплохо разбираюсь в Телеграм API, я решил сделать телеграм канал в который буду раз в сутки постить какое-то астрономическое фото с пояснением в красивом виде, как это сделать? сейчас поясню.
1 - Создаете бота, как создать телеграм бота почитайте тут
2 - Создайте телеграм канал, и добавьте ранее созданного бота в этот канал как администратора
3 - Теперь вы сможете отправлять в свой канал сообщения посредством создания POST запроса, например вот с использованием Python, например ниже отправка картинки с подписью:

Где:
AUTH_TOKEN = Токен бота который вы ранее создали
CHANNEL_NAME = Имя канала, например @my_channel
CAPTION = Текстовая подпись к фото
URL = Ссылка на фото которое отправить в телегу
Естественно можете использовать хоть JavaScript, про остальные методы для телеги можно почитать тут.
Теперь про получения данных из NASA, там все просто, делаете GET запрос на то API которое вы выбрали (на том же сайте предоставляются линки, примерно в таком виде:
https://api.nasa.gov/planetary/earth/imagery?lon=100.75&... , вот DEMO_KEY нужно заменить на от ключ, который вы от NASA получили после заполенния анкеты)
Все, готово😁
То что я сделал, это канал, куда раз в сутки будет публиковаться красивое фото космоса, с описанием и автоматическим переводом на русский язык (после нажатия на ссылку под каждым постом идет переход на telegraph где описание доступно в дух языках, оригинала и русском) + добавлена возможность скачать эту картинку в HD качестве, ссылка на канал -> https://t.me/daily_nasa
Спасибо за внимание😁
Продолжаем серию материалов про создание системы заметок. В этой части мы спроектируем и разработаем RESTful API Service на Go cо Swagger и авторизацией. Будет много кода, ещё больше рефакторинга и даже немного интеграционных тестов.
В первой части мы спроектировали систему и посмотрели, какие сервисы требуются для построения микросервисной архитектуры.
Исходники проекта — в репозитории на GitHub.
Подробности в видео и текстовой расшифровке под ним.
Прототипирование
Начнём с макетов интерфейса. Нам нужно понять, какие ручки будут у нашего API и какой состав данных он должен отдавать. Макеты мы будем делать, чтобы понять, какие сущности, поля и эндпоинты нам нужны. Используем для этого онлайн-сервис NinjaMock. Он подходит, если макет надо сделать быстро и без лишних действий.
Страницу регистрации сделаем простую, с четырьмя полями: Name, Email, Password и Repeat Password. Лейблы делать не будем, обойдемся плейсходерами. Авторизацию сделаем по юзернейму и паролю.
После входа в приложение пользователь увидит список заметок, который будет выглядеть примерно так:
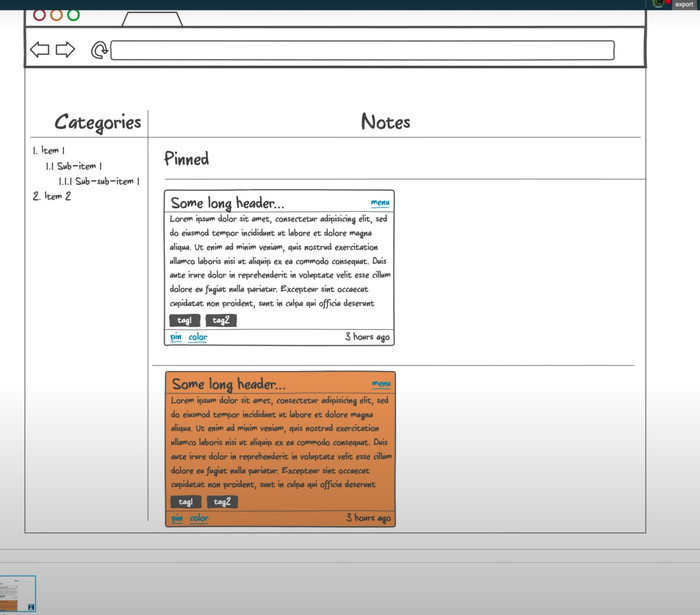
Интерфейс, который будет у нашего веб-приложения:
- Слева — список категорий любой вложенности.
- Справа — список заметок в виде карточек, который делится на два списка: прикреплённые и обычные карточки.
- Каждая карточка состоит из заголовка, который урезается, если он очень длинный.
- Справа указано, сколько секунд/минут/часов/дней назад была создана заметка.
- Тело заголовка — отрендеренный Markdown.
- Панель инструментов. Через неё можно изменить цвет, прикрепить или удалить заметку.
Тут важно отметить, что файлы заметки мы не отображаем и не будем запрашивать у API для списка заметок.
Полная карточка открывается по клику на заметку. Тут можно сразу отобразить полностью длинный заголовок. Высота заметки зависит от количества текста. Для файлов появляется отдельная секция. Мы их будем получать отдельным асинхронным запросом, который не помешает пользователю редактировать заметку. Файлы можно скачать по ссылке, также есть отдельная кнопка на добавление файлов.
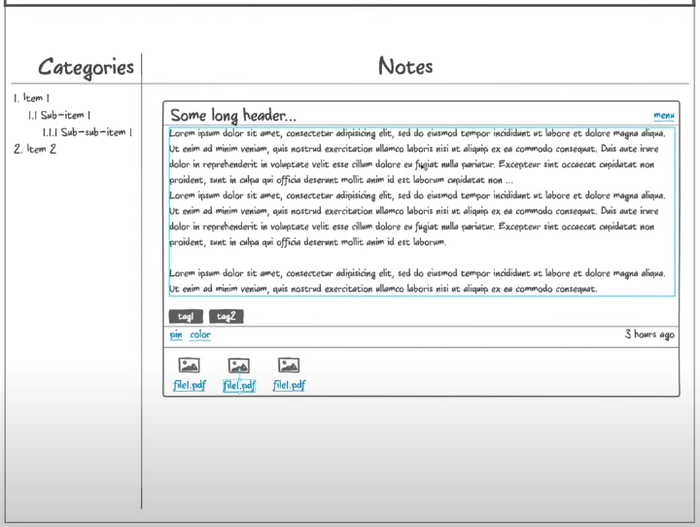
Так будет выглядеть открытая заметка
В ходе прототипирования стало понятно, что в первой части мы забыли добавить еще один микросервис — TagsService. Он будет управлять тегами.
Определение эндпоинтов
Для страниц авторизации и регистрации нам нужны эндпоинты аутентификации и регистрации соответственно. В качестве аутентификации и сессий пользователя мы будем использовать JWT. Что это такое и как работает, разберём чуть позднее. Пока просто запомните эти 3 буквы.
Для страницы списка заметок нам нужны эндпоинты /api/categories для получения древовидного списка категорий и /api/notes?category_id=? для получения списка заметок текущей категории. Перемещаясь по другим категориям, мы будем отдельно запрашивать заметки для выбранной категории, а на фронтенде сделаем кэш на клиенте. В ходе работы с заметками нам нужно уметь создавать новую категорию. Это будет метод POST на URL /api/categories. Также мы будем создавать новый тег при помощи метода POST на URL /api/tags.

Чтобы обновить заметку, используем метод PATCH на URL /api/notes/:uuid с измененными полями. Делаем PATCH, а не PUT, потому что PUT требует отправки всех полей сущности по спецификации HTTP, а PATCH как раз нужен для частичного обновления. Для отображения заметки нам ещё нужен эндпоинт /api/notes/:uuid/files с методами POST и GET. Также нам нужно скачивать файл, поэтому сделаем метод GET на URL /api/files/:uuid.
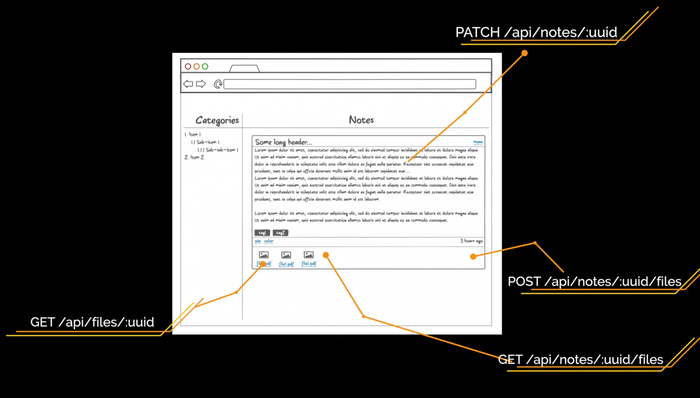
Структура репозитория системы
Ещё немного общей информации. Структура репозитория всей системы будет выглядеть следующим образом:
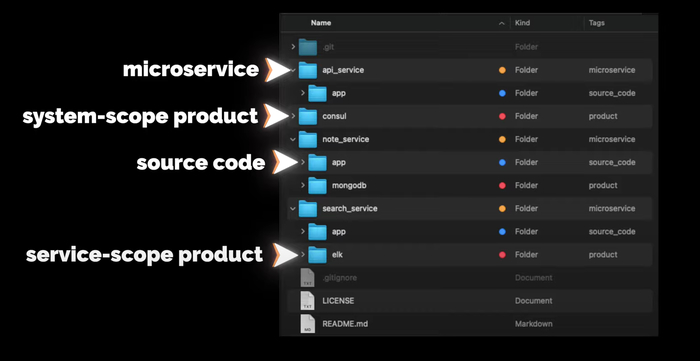
В директории app будет исходный код сервиса (если он будет). На уровне с app будут другие директории других продуктов, которые используются с этим сервисом, например, MongoDB или ELK. Продукты, которые будут использоваться на уровне всей системы, например, Consul, будут в отдельных директориях на уровне с сервисами.
Разработка сервиса
Писать будем на Go
- Идём на официальный сайт.
- Копируем ссылку до архива, скачиваем, проверяем хеш-сумму.
- Распаковываем и добавляем в переменную PATH путь до бинарников Go
- Пишем небольшой тест проверки работоспособности, собираем бинарник и запускаем.
Установка завершена, всё работает
Теперь создаём проект. Структура стандартная:
- build — для сборок,
- cmd — точка входа в приложение,
- internal — внутренняя бизнес-логика приложения,
- pkg — для кода, который можно переиспользовать из проекта в проект.
Я очень люблю логировать ход работы приложения, поэтому перенесу свою обёртку над логером logrus из другого проекта. Основная функция здесь Init, которая создает логер, папку logs и в ней файл all.log со всеми логами. Кроме файла логи будут выводиться в STDOUT. Также в пакете реализована поддержка логирования в разные файлы с разным уровнем логирования, но в текущем проекте мы это использовать не будем.
APIService будет работать на сокете. Создаём роутер, затем файл с сокетом и начинаем его слушать. Также мы хотим перехватывать от системы сигналы завершения работы. Например, если кто-то пошлёт приложению сигнал SIGHUP, приложение должно корректно завершиться, закрыв все текущие соединения и сессии. Хотел перехватывать все сигналы, но линтер предупреждает, что os.Kill и SIGSTOP перехватить не получится, поэтому их удаляем из этого списка.
Теперь давайте добавим сразу стандартный handler для метрик. Я его копирую в директорию pkg, далее добавляю в роутер. Все последующие роутеры будем добавлять так же.
Далее создаём точку входа в приложение. В директории cmd создаём директорию main, а в ней — файл app.go. В нём мы создаём функцию main, в которой инициализируем и создаём логер. Роутер создаём через ключевое слово defer, чтобы метод Init у роутера вызвался только тогда, когда завершится функция main. Таким образом можно выполнять очистку ресурсов, закрытие контекстов и отложенный запуск методов. Запускаем, проверяем логи и сокет, всё работает.
Но для разработки нам нужно запускать приложение на порту, а не на сокете. Поэтому давайте добавим запуск приложения на порту в наш роутер. Определять, как запускать приложение, мы будем с помощью конфига.
Создадим для приложения контекст. Сделаем его синглтоном при помощи механизма sync.Once. Пока что в нём будет только конфиг. Контекст в виде синглтона создаю исключительно в учебных целях, впоследствии он будет выпилен. В большинстве случаев синглтоны — необходимое зло, в нашем проекте они не нужны. Далее создаём конфиг. Это будет YAML-файл, который мы будем парсить в структуру.
В роутере мы вытаскиваем из контекста конфиг и на основании listen.type либо создаем сокет, либо вешаем приложение на порт. Код graceful shutdown выделяем в отдельный пакет и передаём на вход список сигналов и список интерфейсов io.Close, которые надо закрывать. Запускаем приложение и проверяем наш эндпоинт heartbeat. Всё работает. Давайте и конфиг сделаем синглтоном через механизм sync.Once, чтобы потом безболезненно удалить контекст, который создавался в учебных целях.
Теперь переходим к API. Создаём эндпоинты, полученные при анализе прототипов интерфейса. Тут важно отметить, что у нас все данные привязаны к пользователю. На первый взгляд, все ручки должны начинаться с пользователя и его идентификатора /api/users/:uuid. Но у нас будет авторизация, иначе любой пользователь сможет программно запросить заметки любого другого пользователя. Авторизацию можно сделать следующим образом: Basic Auth, Digest Auth, JSON Web Token, сессии и OAuth2. У всех способов есть свои плюсы и минусы. Для этого проекта мы возьмём JSON Web Token.
Работа с JSON Web Token
JSON Web Token (JWT) — это JSON-объект, который определён в открытом стандарте RFC 7519. Он считается одним из безопасных способов передачи информации между двумя участниками. Для его создания необходимо определить заголовок (header) с общей информацией по токену, полезные данные (payload), такие как id пользователя, его роль и т.д., а также подписи (signature).
JWT использует преимущества подхода цифровой подписи JWS (Signature) и кодирования JWE (Encrypting). Подпись не даёт кому-то подделать токен без информации о секретном ключе, а кодирование защищает от прочтения данных третьими лицами. Давайте разберёмся, как они могут нам помочь для аутентификации и авторизации пользователя.
Аутентификация — процедура проверки подлинности. Мы проверяем, есть ли пользователь с полученной связкой логин-пароль в нашей системе.
Авторизация — предоставление пользователю прав на выполнение определённых действий, а также процесс проверки (подтверждения) данных прав при попытке выполнения этих действий.
Другими словами, аутентификация проверяет легальность пользователя. Пользователь становится авторизированным, если может выполнять разрешённые действия.
Важно понимать, что использование JWT не скрывает и не маскирует данные автоматически. Причина использования JWT — проверка, что отправленные данные были действительно отправлены авторизованным источником. Данные внутри JWT закодированы и подписаны, но не зашифрованы. Цель кодирования данных — преобразование структуры. Подписанные данные позволяют получателю данных проверить аутентификацию источника данных.
Реализация JWT в нашем APIService:
- Создаём директории middleware и jwt, а также файл jwt.go.
- Описываем кастомные UserClaims и сам middlware.
- Получаем заголовок Authorization, оттуда берём токен.
- Берём секрет из конфига.
- Создаём верификатор HMAC.
- Парсим и проверяем токен.
- Анмаршалим полученные данные в модель UserClaims.
- Проверяем, что токен валидный на текущий момент.
При любой ошибке отдаём ответ с кодом 401 Unauthorized. Если ошибок не было, в контекст сохраняем ID пользователя в параметр user_id, чтобы во всех хендлерах его можно было получить. Теперь надо этот токен сгенерировать. Это будет делать хендлер авторизации с методом POST и эндпоинтом /api/auth. Он получает входные данные в виде полей username и password, которые мы описываем отдельной структурой user. Здесь также будет взаимодействие с UserService, нам надо там искать пользователя по полученным данным. Если такой пользователь есть, то создаём для него UserClaims, в которых указываем все нужные для нас данные. Определяем время жизни токена при помощи переменной ExpiresAt — берём текущее время и добавляем 15 секунд. Билдим токен и отдаём в виде JSON в параметре token. Клиента к UserService у нас пока нет, поэтому делаем заглушку.
Добавим в хендлер с heartbeat еще один тестовый хендлер, чтобы проверить работу аутентификации. Пишем небольшой тест. Для этого используем инструмент sketch, встроенный в IDE. Делаем POST-запрос на /api/auth, получаем токен и подставляем его в следующий запрос. Получаем ответ от эндпоинта /api/heartbeat, по истечении 5 секунд мы начнём получать ошибку с кодом 401 Unauthorized.
Наш токен действителен очень ограниченное время. Сейчас это 15 секунд, а будет минут 30. Но этого всё равно мало. Когда токен протухнет, пользователю необходимо будет заново авторизовываться в системе. Это сделано для того, чтобы защитить пользовательские данные. Если злоумышленник украдет токен авторизации, который будет действовать очень большой промежуток времени или вообще бессрочно, то это будет провал.
Чтобы этого избежать, прикрутим refresh-токен. Он позволит пересоздать основной токен доступа без запроса данных авторизации пользователя. Такие токены живут очень долго или вообще бессрочно. После того как только старый JWT истекает мы больше не можем обратиться к API. Тогда отправляем refresh-токен. Нам приходит новая пара токена доступа и refresh-токена.
Хранить refresh-токены на сервере мы будем в кэше. В качестве реализации возьмём FreeCache. Я использую свою обёртку над кэшем из другого проекта, которая позволяет заменить реализацию FreeCache на любую другую, так как отдает интерфейс Repository с методами, которые никак не связаны с библиотекой.
Пока рассуждал про кэш, решил зарефакторить существующий код, чтобы было удобней прокидывать объекты без dependency injection и синглтонов. Обернул хендлеры и роутер в структуры. В хендлерах сделал интерфейс с методом Register, которые регистрируют его в роутере. Все объекты теперь инициализируются в main, весь роутер переехал в мейн. Старт приложения выделили в отдельную функцию также в main-файле. Теперь, если хендлеру нужен какой-то объект, я его просто буду добавлять в конструктор структуры хендлера, а инициализировать в main. Плюс появилась возможность прокидывать всем хендлерам свой логер. Это будет удобно когда надо будет добавлять поле trace_id от Zipkin в строчку лога.
Вернемся к refresh_token. Теперь при создании токена доступа создадим refresh_token и отдадим его вместе с основным. Сделаем обработку метода PUT для эндпоинта /api/auth, а в теле запроса будем ожидать параметр refresh_token, чтобы сгенерировать новую пару токена доступа и refresh-токена. Refresh-токен мы кладём в кэш в качестве ключа. Значением будет user_id, чтобы по нему можно было запросить данные пользователя у UserService и сгенерировать новый токен доступа. Refresh-токен одноразовый, поэтому сразу после получения токена из кэша удаляем его.
Описание API
Для описания нашего API будем использовать спецификацию OpenAPI 3.0 и Swagger — YAML-файл, который описывает все схемы данных и все эндпоинты. По нему очень легко ориентироваться, у него приятный интерфейс. Но описывать вручную всё очень муторно, поэтому лучше генерировать его кодом.
- Создаём эндпоинты /api/auth с методами POST и PUT для получения токена по юзернейму и паролю и по Refresh-токену соответственно.
- Добавляем схемы объектов Token и User.
- Создаём эндпоинты /api/users с методом POST для регистрации нового пользователя. Для него создаём схему CreateUser.
Понимаем, что забыли сделать хендлер для регистрации пользователя. Создаём метод Signup у хенлера Auth и структуру newUser со всеми полями для регистрации. Генерацию JWT выделяем в отдельный метод, чтобы можно было его вызывать как в Auth, так и в Signup-хендлерах. У нас всё еще нет UserService, поэтому проставляем TODO. Нам надо будет провалидировать полученные данные от пользователя и потом отправить их в UserService, чтобы он уже создал пользователя и ответил нам об успехе. Далее вызываем функцию создания пары токена доступа и refresh-токена и отдаём с кодом 201.
У нас есть подсказка в виде Swagger-файла. На его основе создаём все нужные хендлеры. Там, где вызов микросервисов, будем проставлять комментарий с TODO.
Создаём хендлер для категорий, определяем URL в константах. Далее создаём структуры. Опираемся на Swagger-файл, который создали ранее. Далее создаём сам хендлер и реализуем метод Register, который регистрирует его в роутере. Затем создаём методы с логикой работы и сразу пишем тест API на этот метод. Проверяем, находим ошибки в сваггере. Таким образом мы создаём все методы по работе с категориями: получение и создание.
Далее создаём таким же образом хендлер для заметок. Понимаем, что забыли методы частичного обновления и удаления как для заметок, так и для категорий. Дописываем их в Swagger и реализуем методы в коде. Также обязательно тестируем Swagger в онлайн-редакторе.
Здесь надо обратить внимание на то, что методы создания сущности возвращают код ответа 201 и заголовок Location, в котором находится URL для получения сущности. Оттуда можно вытащить идентификатор созданной сущности.
В третьей части мы познакомимся с графовой базой данных Neo4j, а также будем работать над микросервисами CategoryService и APIService.
Взять с собой побольше вкусняшек, запасное колесо и знак аварийной остановки. А что сделать еще — посмотрите в нашем чек-листе. Бонусом — маршруты для отдыха, которые можно проехать даже в плохую погоду.







