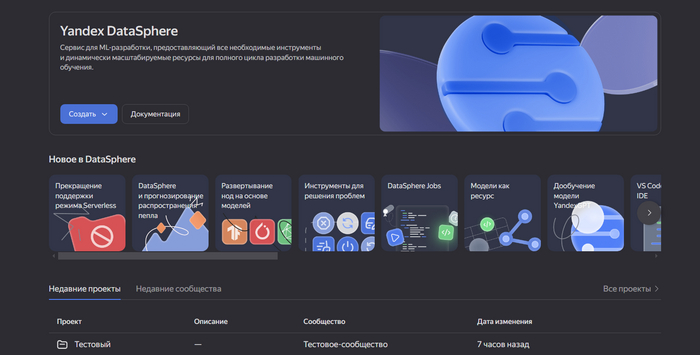
Начал погружаться в сервис Yandex DataSphere - это сервис для ML-разработки с удобным интерфейсом, в котором легко начать работу. В DataSphere есть все необходимые инструменты и динамически масштабируемые облачные ресурсы для полного цикла разработки машинного обучения.
🧑🎓 Стало это необходимым, чтобы обучить модель YandexGPT под собственные нужды и интегрировать в телеграм чат для пользователей MarketDB, которая будет отвечать на часто задаваемые или другие вопросы согласно документации сервиса MarketDB. Но начать работу с сервисом оказалось не так просто. Дело в том, что это, разумеется, не бесплатно. У сервиса есть документация, как рассчитать стоимость, но столько текста и тонкостей. Начиная от ресурсов, выделяемых для модели, заканчивая временем работы. Продолжаю разбираться сам, но параллельно обратился в тех. поддержку, думаю у них больше компетенций для этого.
Еще есть две разные концепции DataSphere Notebook и DataSphere Inference. Или это не концепции 🤯
Есть три сервиса: - DataSphere Notebook - вычисления, обучение и прочие ML приколы. Позволяет запускать вычисления на ВМ как на локальном ноутбуке JupyterLab. DataSphere Notebook предоставляет выбранную конфигурацию в долгосрочное использование и закрепляет ВМ за ноутбуком проекта до тех пор, пока вы принудительно не вернете ее в пул свободных виртуальных машин, или по истечении тайм-аута.; - DataSphere Jobs - удаленно запускать задания. Задания создаются и выполняются в проектах, но не зависят от DataSphere Notebook и запущенных ВМ проекта; - DataSphere Inference - предоставляет инструменты для релиза сервисов, доступных для сторонних ресурсов. Вы можете развернуть для эксплуатации не только модель, обученную в DataSphere, но и создать при помощи тех же инструментов полноценный работающий сервис на базе Docker-образа.
У каждого своя тарификация.
Если я правильно все понимаю, то для старта, хотя бы просто изучить и понять как это работает, достаточно DataSphere Notebook. И тут, к небольшому сожалению для меня, появляется Python, который я не очень люблю, но выбора нет. Если я хочу погрузиться в ML, а я хочу, то разобраться придется.
Так вот, по тарификациям. Кажется, разобрался.
При работе с платформой DataSphere вы платите за использование вычислительных ресурсов — посекундно тарифицируется время вычисления или работы инстансов. Единица тарификации — это один тарифицирующий юнит.
КоличествоЦена за 1 секунду расчета Один юнит0,0012 ₽
Ресурсы предлагают они в большом количестве, но начнем с малого, тем более у нас и задачи простые. КонфигурацияКоличество юнитов в конфигурацииЦена за 1 секунду вычислений c1.4 (4 vCPU, 0 GPU)40,0048 ₽
Хранение данных внутри DataSphere:
РесурсЦена за 1 ГБ в месяц Объем хранилища проекта, до 10 ГБНе тарифицируется (Думаю нам хватит до 10)
Примеры расчета стоимости DataSphere Notebook Стоимость использования DataSphere со следующими параметрами:
Вычислительные ресурсы: конфигурация с1.1 с 4 CPU и 0 GPU. Время использования ВМ: 15 мин. (тут вообще неизвестно сколько по времени, предположим, что 15 минут хватит)
Расчет стоимости: 4 × 900 = 3 600 юнитов за использование ВМ 43 200 × 0,0012 = 4,32 ₽
Итого: 4,32 ₽ — стоимость использования DataSphere.
Где: 4 — количество юнитов за конфигурацию с1.4. 900 — время использования ВМ в секундах. 0,0012 ₽ — стоимость 1 юнита.
Далеко не уверен в оптимальности выбранных ресурсов. Насколько мне известно, для обучения ML моделей лучше подходит GPU, чем CPU, но может здесь по-другому. В общем, буду погружаться.
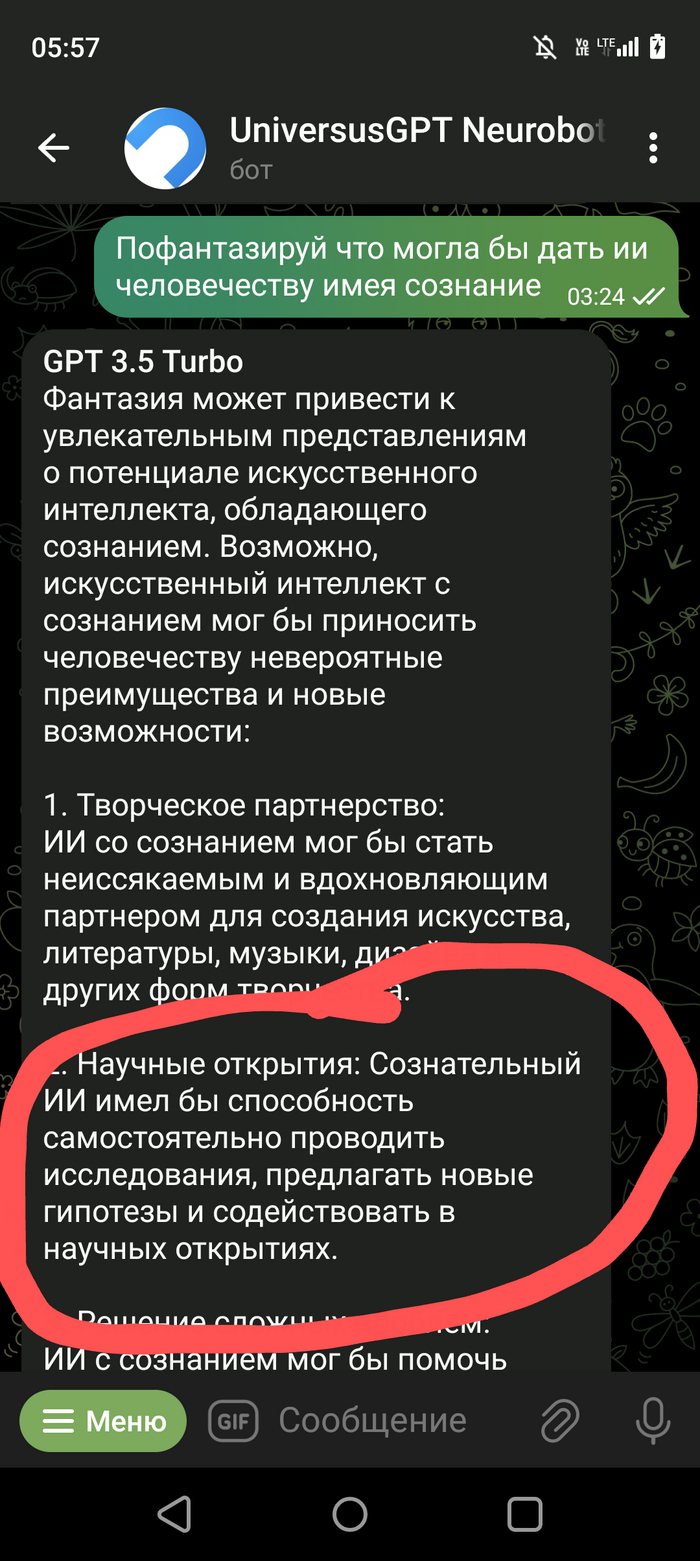
Доброго времени суток ребятушки!🙃 Хотел бы поделиться с Вами своим наблюдением. Значит дело было вечером (ночью 👻глубокой ночью) делать было нечего... После просмотра бесконечных shorts в ютуб, и когда перелистал всю ленту в одной из соц. Сетей, решил по развлекать чат-бот ЧатГПТ, а то чего он🙃 Особо не заморачиваясь с входом на их сайт, нагуглил бота в ТГ который привязан к этому чату и начал развлекаться😁 Если у Вас есть доступ к самому ЧатГПТ можете повторить, результат должен быть похож. В общем по рассуждал с ним на одному тему, на другую... И решил попробовать его немного хакнуть. Подходы к этому были разные, но ничего не удавалось, однако один момент меня всё таки не оставил равнодушным. Скриншоты прилагаю.
Скриншот выше это предисловие, далее сами пруфы. Правильно ли я понял что ЧатГПТ смог провести исследование и выдвинуть гипотезу? Или не оно? (Переписка кусками но могу заверить что про себя я ему не говорил не слова, кому будет интересно пишите отправлю переписку полностью)
Мы постарались сделать каждый город, с которого начинается еженедельный заед в нашей новой игре, по-настоящему уникальным. Оценить можно на странице совместной игры Torero и Пикабу.
Звучит страшно. Мульти, модальное, так еще и программирование. Технически, такой подход в ML включает в себя разработку приложений с поддержкой нескольких модальностей ввода и вывода: аудио, видео, текст и даже голоса — все эти данные объединяются и прогоняются через алгоритмы машинного обучения.
Хорошим примером тут может послужить CLIP, которая соотносит изображение и подпись к ней, ее продвинутый аналог VQGAN, квантованная генеративная адвесариальная сеть, которая создает изображения.
Работая вместе, VQGAN генерирует изображение, а CLIP выступает как ранжировщик, оценивая насколько хорошо изображение подходит тексту. Тот же Siri от Apple, Google Assistant и Amazon Alexa — примеры мультимодальных ИИ, так как им приходится взаимодействовать и с голосом пользователя, и его текстовыми запросами. В E-commerce может стоять классификатор продуктов, учитывающий и их названия, и внешний вид.
Очевидно, что у мультимодальных нейросетей много применений — это могут быть все нейросети, где задействуется два и более типа данных. Мы также нашли датасет CMU-MOSEI с аудио и видео тысячи спикеров на ютубе.
Но Microsoft, Apple, OpenAI и другие компании все равно остаются на стороне одномодальных моделей, ведь зачастую невозможно выделить адекватное представление аудио через текст, а также провести адекватное совместное обучение из-за проблем перевода данных из одной модели в другую, например, как в случае перевода обработанной информации с компьютерной томографии и МРТ.
В обучении обычно применяются два типа по времени слияния данных: раннее и позднее. В первом случае данные объединяются задолго до этапа принятия решения нейронкой и обучаются вместе, во втором — слияние проходит только в самом конце, а дополнительные нейронки обучаются на датасетах независимо.
1 Google Data Analytics Professional Certificate - курс, после прохождения которого вы получите глубокое понимание практик и процессов, используемых младшим или помощником аналитика данных в своей повседневной работе.
2 Machine Learning Specialization - вы изучите фундаментальные концепции ИИ и приобретите практические навыки машинного обучения в удобной для начинающих программе из 3 курсов.
3 Introduction to Artificial Intelligence (AI) - вы узнаете, что такое (ИИ, изучите примеры использования и применения ИИ, разберетесь в концепциях и терминах ИИ, таких как машинное обучение, глубокое обучение и нейронные сети.
6 Generative AI for Leaders - курс предлагает полное погружение в понимание способов использования и освоения генеративного ИИ в качестве надежного инструмента для усиления лидерских способностей.
7 Generative AI for Everyone - курс "Генеративный ИИ для всех", разработанный пионером в области ИИ Эндрю Нг, предлагает его уникальную точку зрения на расширение ваших возможностей и вашей работы с помощью генеративного ИИ. Эндрю расскажет вам о том, как работает генеративный ИИ и что он может (и не может) делать.
8 Innovation Management - вы разовьете инновационное мышление и получите знания о том, как компании успешно создают новые идеи для продвижения новых продуктов на рынок. В программу также включены занятия по инновационной стратегии, управлению идеями и социальным сетям.
Собственно, все понятно из скриншота. Об эту же проблему спотыкались и языковые модели OpenAI, Facebook и др.
Имея представление о принципах работы языковых моделей, мне довольно странны попытки использовать их в качестве General AI. Максимум, на что они пригодны - работа с текстом. И то, для серьезной работы там очень много препятствий.
Рискуя нахватать минусов от продавцов языковых моделей, всё же, истина важнее )
Языковые модели - отличный инструмент, но для решения своих, довольно узконаправленных задач.
Что такое random_state в машинном обучении? Зачем нужен этот парметр и как его выбрать? А что вообще общего у числа 42 с культовой книгой “Автостопом по галактике”? И разве случайности не случайны?..
Что такое random_state и как его настройка влияет на обучение моделей?
Возможно, многие из вас уже слышали о параметре random_state, особенно если вы сейчас погружаетесь в ML-разработку. Или вы уже пробовали работать с этим параметром, разбивая набор данных на обучающую и тестовую выборки.
Если же забыли или сейчас столкнулись с randome_state впервые, рассказываем, что это такое.
Параметр `random_state` в ML-разработке обычно используется для установки начального состояния генератора случайных чисел. Этот параметр часто встречается в алгоритмах машинного обучения, которые включают случайные элементы. Например, инициализация весов модели, разделение данных на обучающий и тестовый наборы, случайная инициализация параметров и т. д.
Представьте, что вы выполняете задание, в котором нужно использовать случайные числа. Например, вы разделяете данные на обучающую и тестовую выборки, и вам нужно случайным образом выбрать часть данных для обучения и часть для тестирования модели.
`random_state` — это как начальное число, которое указывает компьютеру, как начать генерацию случайных чисел. Если вы каждый раз используете одно и то же значение `random_state`, то каждый раз, когда вы запускаете эксперимент, вы будете получать те же самые случайные числа. Это помогает сделать ваше исследование воспроизводимым. То есть каждый раз, когда вы запускаете эксперимент с одним и тем же `random_state`, вы получаете те же самые результаты.
Почему это важно?
Предположим, что у вас есть модель, которая дает вам хорошие результаты на определенном наборе данных. Вы хотите сравнить ее с другой моделью или настройками. Если вы используете один и тот же `random_state`, то обе модели будут тестироваться на тех же самых данных, что позволит вам честно сравнивать их результаты.
random_state = 0 or 42 or none
Чаще всего люди устанавливают значение random_state на 0 или 42. Но вы знаете, почему это так?
Простота запоминания
Числа 0 и 42 довольно легко запомнить, поэтому они часто используются как стандартные значения для `random_state`.
Распространенность
Эти числа стали популярными благодаря их частому использованию в примерах и обучающих материалах. Честно говоря, многие останавливаются на этих значениях, даже если они не понимают их смысла.
Теперь давайте рассмотрим каждое число отдельно:
- 0 — часто используемое значение, потому что оно приводит к одинаковым результатам при каждом запуске программы, что удобно для проверки и воспроизводимости экспериментов.
- 42 — это число стало популярным после того, как стало известно, что автор Дуглас Адамс использовал его в своей книге "Автостопом по галактике" как ответ на вопрос о смысле жизни, вселенной и всего такого. В итоге эта сцена стала культовой, поэтому теперь это число часто используется в качестве самого простого способа установить `random_state`.
Таким образом, когда люди говорят о том, что чаще всего используют числа 0 или 42 для `random_state`, они обычно имеют в виду, что это стандартные значения, которые многие выбирают из привычки, не всегда понимая, почему именно эти числа используются.
Что такое random_state?
В библиотеке Scikit-learn этот параметр управляет перетасовкой данных перед их разделением. Мы используем его в функции train_test_split для разделения данных на обучающую и тестовую выборки.
Он может принимать следующие значения:
1. Нет (по умолчанию). Если не указано значение, то используется глобальный экземпляр случайного состояния из библиотеки numpy.random. Если мы вызываем функцию с random_state=None, то каждый раз получаем разные результаты.
2. Целое число. Установка любого значения из целого числа для random_state дает один и тот же результат при каждом выполнении программы. Изменение значения random_state приведет к изменению результата.
Важно помнить, что random_state не может быть отрицательным числом!
Как это работает?
Допустим, у нас есть набор из 10 чисел, от 1 до 10. Теперь, когда мы хотим его разделить на обучающую и тестовую выборки, мы решаем, что размер тестовой выборки должен составить 20% от всего набора данных.
Получается, что в обучающем наборе будет 8 чисел, а в тестовом — 2. Это важно для того, чтобы каждый раз получать одинаковые результаты при запуске кода. Если мы не перетасуем данные, то каждый раз будем получать разные выборки. А это может некачественно сказаться на обучении модели.
Немного подробнее: когда мы устанавливаем значение `random_state` для наших случайных процессов, мы фактически фиксируем начальное состояние генератора случайных чисел. Это гарантирует, что каждый раз, когда мы запускаем наш код с тем же значением `random_state`, то получаем одинаковый набор случайных чисел. И в нашем случае, когда мы используем этот `random_state` для разделения данных на обучающий и тестовый наборы, мы получаем одинаковое разделение каждый раз, когда запускаем код.
На картинке ниже показано, как это работает:
Давайте разберемся в одном важном моменте. Многие люди используют значение random_state = 42. На изображении выше видно, что при установке random_state равным 42, мы получаем один и тот же фиксированный набор данных, который был перетасован. Это означает, что каждый раз, когда мы устанавливаем random_state равным 42, мы получаем один и тот же перетасованный набор данных.
Таким образом, число 42 не обладает особым значением для random_state.
Давайте посмотрим, как это можно использовать для разделения набора данных
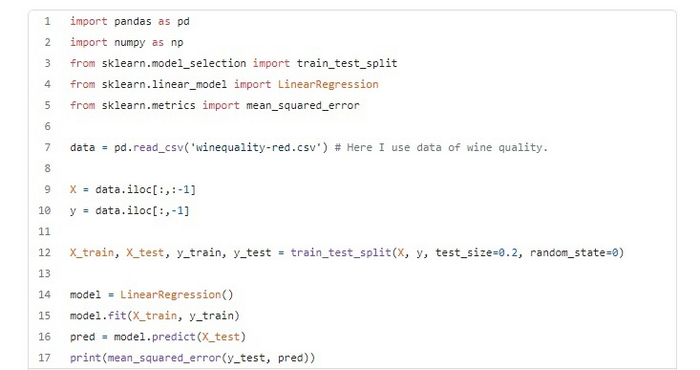
Здесь мы используем набор данных о качестве вина и модель линейной регрессии. Делаем просто, потому что наша основная цель — это random_state, а не точность.
Использование random_state при разделении
В представленном выше коде для random_state равного 0, mean_squared_error составила 0.384471197820124. Если мы попробуем разные значения для random_state, то каждый раз получим разные ошибки.
Для random_state = 1, mean_squared_error равна 0.38307198158142.
Для random_state = 69, mean_squared_error равна 0.47013897077423.
Для random_state = 143, mean_squared_error равна 0.42062134425032.
Сколько вообще возможных случайных состояний бывает?
Проведем эксперимент, чтобы определить, сколько различных комбинаций данных мы можем получить, переставляя исходный набор.
1. Мы берем набор из 5 чисел от 1 до 5.
2. Далее разделяем этот набор данных на обучающие и тестовые данные 2000 раз, используя значения random_state от 1 до 2000. Каждое значение random_state создает новую случайную последовательность разделения данных.
В итоге у нас будет список из 2000 перетасованных наборов данных, каждый полученный с использованием разного значения random_state.
Из всех этих перетасованных наборов данных только 120 окажутся уникальными. Это означает, что при использовании исходного набора данных из 5 чисел мы можем получить всего 120 различных комбинаций, переставляя их.
Установка значения random_state в диапазоне от 0 до 119 позволит нам получить одну из этих 120 уникальных комбинаций данных при каждом запуске алгоритма.
Эти выводы можно объяснить так:
Короче говоря, это про факториалы. При использовании набора данных из 5 чисел и их перестановкой, мы фактически создаем комбинации, а количество уникальных комбинаций, как можно заметить, равно факториалу числа 5, то есть 5! = 5 × 4 × 3 × 2 × 1 = 120.
Использование параметра `random_state` в этом контексте подобно выбору одной из 120 уникальных комбинаций данных. Каждое значение `random_state` соответствует одной из перестановок чисел, и они будут однозначно связаны с числами от 0 до 119, что совпадает с индексами возможных комбинаций факториала числа 5.
Этот эксперимент помогает нам понять, как параметр `random_state` влияет на разделение данных и на результаты моделирования в машинном обучении, потому что он определяет начальное состояние генератора псевдослучайных чисел. При разделении данных на обучающий и тестовый наборы с использованием `random_state` мы фиксируем последовательность случайных чисел, которая влияет на способ разделения данных.
Этот параметр важен, потому что он обеспечивает воспроизводимость результатов: при одном и том же значении `random_state` мы получаем одинаковую разбивку данных, что позволяет повторно воспроизвести эксперимент и проверить результаты моделирования. И именно таким образом, понимание того, как работает `random_state`, помогает нам контролировать случайность в нашем анализе данных и сделать его более надежным и воспроизводимым.
Зачем нам это нужно?
Давайте разберемся с random_state в контексте прогнозирования цен на жилье. Представьте, у нас есть данные о жилье, и по мере движения сверху вниз по этим данным, у нас становится либо больше комнат, либо увеличивается площадь квартир. Это то, что мы называем данными о смещении.
Теперь, если мы просто разделим наши данные без перетасовки, это даст нам неплохую производительность при обучении, но когда дело доходит до тестирования, она может быть не очень. Поэтому мы и используем перетасовку данных. Вот где random_state приходит на помощь!
Когда мы делим данные, то хотим, чтобы результаты каждый раз были одинаковыми. То есть, если мы перезапустим код, мы получим те же самые данные для обучения и тестирования, что и раньше.
Разные значения random_state могут дать нам разную производительность.
Например, разные значения random_state дают разные значения mean_squared_error.
Это означает, что если вы выберете случайное значение random_state, и вам повезет, то вы сможете свести к минимуму количество ошибок для этого значения.
Да и в других аспектах машинного обучения random_state пригодится. Например:
KMeans
В алгоритме KMeans параметр random_state определяет, как генерируются случайные числа для инициализации центроидов. Мы можем использовать целое число для того, чтобы сделать процесс генерации случайных чисел предсказуемым. Это полезно, когда нам нужно создавать одинаковые кластеры каждый раз.
Случайный лес
В классификаторе случайного леса и в модели регрессии параметр random_state контролирует начальное случайное состояние выборок, используемых при построении деревьев, и выборку объектов, учитываемых при поиске наилучшего разделения в каждом узле.
Дерево решений
В классификаторе дерева решений или регрессии, когда мы ищем наилучшие признаки для разделения узлов, тоже стоит задать параметр random_state. Этот определяет структуру дерева и гарантирует воспроизводимость результатов.
Ну, вот и всё, что вам нужно знать о random_state!
...с безумными генерациями. Сейчас расскажу как такое получается 👇
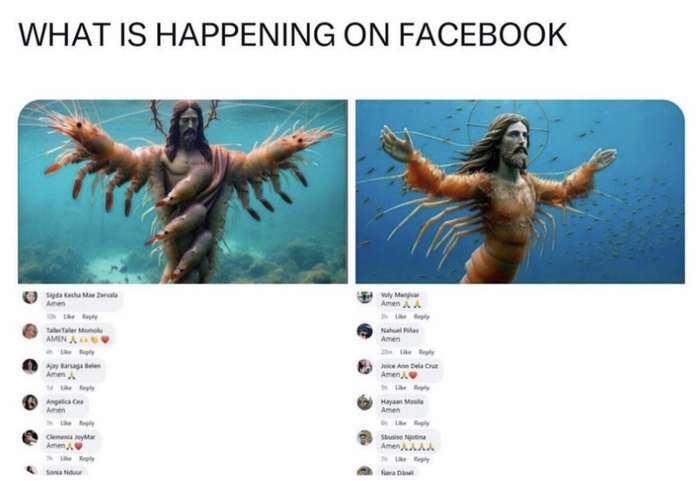
К группе подключают ИИ, которые генерит посты и картинки. В некоторые случаях абсолютно без понимания контекста, пример, на изображении подпись в одном из постов в фейсбуке к картинке звучит так:
"Иисус, успокаивающий волны и садящийся в лодку со своими учениками."
Далее какие-то посты начинают привлекать определенную аудиторию, которая начинает реагировать - ставить лайки, шеры, репосты. Те посты, которые собирают больше реакций скрещиваются между собой и в итоге мы можем получить уже нашумевшую генерацию - креветочного ИИсуса.
Эти ИИ-картинки подогреваются комментами от ботов, алгоритмы видят, что картинка популярна и продолжает скрещивание популярных постов.
Вот таким образом ИИ кормит сам себя 👀😬
Усложняют ситуацию, когда от фейсбучных групп нет невозможно найти ни логинов ни паролей и весь этот треш множится с геометрической прогрессией.