


Ищу книгу А.А. Кубенский - Алгоритмы и структуры данных
Может быть у кого-нибудь лежит данная книга?
Готов купить.
Ищу бумажный вариант.

Показать полностью
1
Может быть у кого-нибудь лежит данная книга?
Готов купить.
Ищу бумажный вариант.
Всем привет, меня зовут Артем и я люблю программировать.

Источник картинки [https://rozetked.me/articles/1336-yandeks-kotiki-i-schenochk...]
Сегодня я хочу рассказать вам о структурах данных: что это, зачем нужны и почему это одна из самых важных составляющих программирования. Также в этой статье рассмотрим три простые структуры — стек(stack), очередь(queue) и связной список(linked list).
Как я уже говорил ранее, программирование — это правильная манипуляция данными. Даже если вы не делаете вычислений, а пишите логику кнопки или верстаете сайт — вы все равно манипулируете данными. И вам просто необходимо знать, как правильно управлять и организовывать данный, что бы ваши программы работали должным образом.
Что дает знание структур данных?
1) Ваши программы оптимизированы и затрачивают только необходимое количество ресурсов. Многие алгоритмы зависят от правильно подобранных структур данных.(правильно подобранные структуры данных — это только один из методов оптимизации).
2) Вы понимаете, как работает ваш код (или код другого человека)
3) Вы пишете более понятный код, где все разложено по своим местам. В таком коде другому программисту (или вам сами) будет проще ориентироваться.
Сами по себе структуры данных — это абстрактные "картонные коробки", в которые вы можете положить и достать свои вещи. В некоторых коробках все вещи могут быть перемешаны, в других — вещи должны быть сложены аккуратно и красиво. Есть коробки, которые достаточно просты по своей структуре — открыл коробку, достал нужную вещь. Но некоторые коробки смогут содержать в себе еще пару коробочек. Иногда в контейнерах нельзя хранить две одинаковые вещи, иногда — можно. В общем, вы должны представлять структуру данных как контейнер, в который можно класть и забирать данные. Как эти данные там хранятся — это уже другой разговор, и в большинстве случаев у вас будут все необходимие инструменты по манипуляции этим данными (вам будет все равно, как эти данные там лежат).
Стек
Стек — это одна из простейших структур. Данные в ней хранятся по принципу FILO - первый зашел, последний вышел. Представим, что ваши данные — это кирпичи. Сначала вы положили один кирпич в стек, на него вы кладете второй (используя стек, вы всегда кладете данные сверху на предыдущие). Теперь, что бы достать первый кирпич, нам нужно для начала снять с него второй. То есть, когда мы захотим доставать данные из стека, нам прийдется начинать с того кирпича (тех данных), который лежит на самом верху.
Где применяется эта хрень? Представьте себе, что вы работаете в программе Microsoft Word (для тех, кто не работал, представьте программу Photoshop) [если не работали и там и там, представьте себе любую программу, в которой нажатия клавиш Ctrl + Z отменяет последнее действие]. Так вот, когда вы совершаете какое-либо действие в программе, она закидывает совершенное действие в стек. Самый верхний кирпич стека — это состояние вашего документа\фотографии\чего-либо другого на текущий момент. Когда вы хотите отменить последнее изменение (вернуться на одно действие назад), программа берет самый верхний кирпич(последнее действие) со стека, выбрасывает его и кирпич, который был под ним — теперь самый верхний (теперь он становится текущим состоянием). Сам по себе стек очень прикольная структура данных (хотя иногда ее лучше заменить чем-то другим).
Сложность базовых операций в стеке:
Добавить элемент в стек O(1)
Удалить элемент со стека O(1)
Проверить, пуст ли стек O(1)
Как мы знаем из предыдущей статьи, меньшей сложности, чем O(1), пока не существует, что делает стек очень быстрой и малозатратной(по памяти) структурой данных.
Очередь
Очередь — структура, очень похожая на стек, но работает немного по другому — по принципу FIFO - первый пришел, первый вышел. То есть очередь работает так же, как и очередь в реальной жизни — люди стают один за другим (тот, кто раньше всех пришел, стоит самый первый). Самые первые данные, которые мы положили, мы и возьмем самыми первыми.
Пример применения очереди приведу из собственной жизни — однажды мне нужно было написать функцию, которая бы разделила предложение на слова. Каждое слово я представлял в виде очереди, и, начиная с первого символа строки, шел по ней, запихивая каждый символ в очередь, пока не натыкался на знак пробела. Из-за того, что я клал один символ в очередь, каждый следующий символ подвигал предыдущий. То есть, начиная с первой буквы слова, я знал, что буквы не перепутаются в структуре и будут в таком же порядке, как они написаны в предложении.
Далее мне нужно было выполнить еще одно условие — слова должны быть в таком порядке, как они были в предложении. И тут мне снова помогла очередь. Я представил предложение как очередь из людей, где каждый человек был отдельным словом. И как только я доходил до конца слова (натыкался на знак пробела), я клал очередь-слово в очередь-предложение. Так у меня вышла очередь из очередей, где каждое слово было на своем месте.
Сложность базовых операций:
Добавить элемент O(1)
Удалить элемент O(1)
Связной список
Связной список
Последняя структура данных на сегодня — связной список. Эта штука мало чем отличается от стандартного массива (просто набор данных, которые доступны по индексу). Главная особенность связного списка это то, что каждая ячейка данных в списке имеет связь со следующей ячейкой (таким образом, только ячейка знает, где находиться ее сосед, идущий после нее). С помощью такой структуры данные могут быть физически разбросаны по оперативной памяти, но логически составлять одну структуру данных. Через связной список можно реализовать много других структур. Сама ячейка содержит в себе данные и указатель на соседа.
Сложность базовых операций:
Добавить элемент O(1)
Удалить элемент O(1)
В структурах данных нет ничего сложного, но они очень важны в программировании. В следующей (последней), части мы поговорим о графах, деревьях, хеш-таблицах (будет интересно) и коллекциях.
[Еще скоро будет перевод статьи про Arch Linux и его установке рядом с Windows 10]
Выспаться, провести генеральную уборку, посмотреть все новые сериалы и позаниматься спортом. Потом расстроиться, что время прошло зря. Есть альтернатива: сесть за руль и махнуть в путешествие. Как минимум, его вы всегда будете вспоминать с улыбкой. Собрали несколько нестандартных маршрутов.
Привет, меня зовут Артем и я люблю программировать. Надеюсь, вы прочитали предыдущую, нулевую статью.
Что бы стать хорошим программистом (не веб-разработчиком, а хорошим программистом), вы в первую очередь должны понять, что программирование – это манипуляция данными. И то, насколько вы хорошо умеете обращаться с данными в зависимости от поставленной задачи, определяет, сможете ли вы создавать хорошие программы или нет. В интернете уже есть куча материала на тему структур данных и алгоритмов, но я попробую расписать весь этот материал по-своему. Возможно, это поможет кому-то лучше понять эту тему.
Начнем с определения понятия «сложность алгоритма» — это нам пригодится тут и в следующей статье про алгоритмы.
Если говорить простыми словами – то сложность алгоритма – это то, сколько действий нужно совершить данному алгоритму, чтобы выполнить определенную задачу. Чем больше действий нужно алгоритму, тем он сложнее, и тем он хуже (если существуют альтернативные алгоритмы с меньшей сложностью).
Например, представим ряд чисел – 12345. Нам нужно инвертировать порядок этих чисел (переставить числа так, чтобы вышло 54321). Представим, что алгоритму №1 нужно совершить 5 действий, чтобы переставить числа, а алгоритму №2 – 10. Из этого можем сделать вывод, что в данном случае алгоритм №1 будет предпочтительней для нас.
Но это говоря простыми словами. В реальности на выбор алгоритма также влияет то, сколько памяти он занимает в процессе работы (например, у алгоритма высокая сложность, но он кушает мало памяти, и для устройств с малым количеством оперативной памяти лучше реализовать его), сложность реализации алгоритма (например, мы знаем, что алгоритм «быстрой сортировки» быстрее, чем алгоритм «сортировки пузырьком». Но у вас в компании работают только веб-программисты, которые написать алгоритм быстрой сортировки не смогут. Поэтому вам ничего не остается, кроме реализации алгоритма «сортировки пузырьком») и требования алгоритма к железу (в основном это алгоритмы для нейросетей, которые работают на видеокартах. Например, что бы прогнать картинку 512х512 пикселей через нейросеть типа ESRGAN, вам потребуется видеокарта, у которой не менее 2 ГБ видеопамяти).
Сложность алгоритма обозначается большим О. Например, O(1), O(n), O(n!). И тут все сложна легко. Вспоминаем математику, на которой ты стрелял в друга скомканными шариками из ручки, что значение функции может зависеть (или не зависеть) от определенных параметров этой функции. Например, функция 1 = n (это то же самое, что и O(1)) говорит, что независимо от значения n результат всегда будет 1. Функция y = n! (это O(n!)) означает, что результат (это y) будет равняться значение n факториал (не путать с фракталом). То есть, если у нас 5 чисел, то алгоритм сложностью O(n!) сделает 1 * 2 * 3 * 4 * 5 операций (посчитай сам, сколько это).
Лично мне нравиться эта табличка, которую я нашел в группе /dev/null в ВК
Другой взгляд на О большое:
O(1) = O(уууее)
O(log n) = O(да)
O(n) = O(к)
O(n^2) = O(йблин)
O(2^n) = O(нет)
O(n!) = O(МГ!)
Как это связано со структурами данных? Структуры данных и алгоритмы очень тесно связаны, и у каждой структуры есть свои алгоритмы обхода элементов структуры, их добавление\удаление, поиск в структуре и т.д. И поэтому важно знать сложность алгоритмов, которые дают нам возможность управлять этой структурой, что бы выбрать подходящую для решения нашей задачи.
Со сложностью алгоритмов вроде разобрались. На практике для каждой задачи есть несколько решений, и вы сами, как программист, вольны выбрать то, которое подходит именно под вашу ситуацию.
В следующей статье я попробую рассказать о структурах данных, зачем они нужны и рассмотреть такие структуры, как стек, очередь и связанный список.
После прочтения данного текста можете заглянуть в комментарии - там могут дополнить материал или исправить ошибки в данном материале.
Всем привет. Я хочу поделиться с вами библиотекой структур данных для языка C. Интерфейс библиотеки напоминает интерфейс стандартной библиотеки C++. Буду рад любому фитбэку.
Ссылка на публичный репозиторий: https://github.com/maksimandrianov/cdcontainers
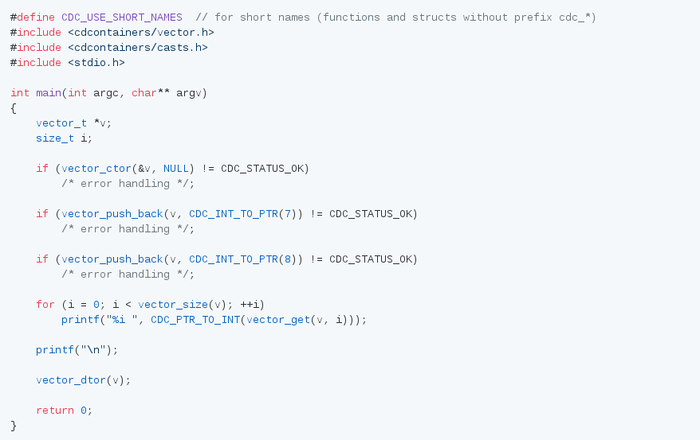
Ниже на картинке представлен аналог vector из C++.
Хеш-таблица (hashtable) — это структура данных, представляющая собой специальным образом организованный набор элементов хранимых данных. Все данные хранятся в виде пар хеш-значения. Данная структура похожа на словарь (map), но имеет особенности такие как применение хеш-функции для увеличения скорости поиска. Принцип работы данной структуры схож с каталогом книг. Все книги разложены в алфавитном порядке, но не на одном стеллаже, а для каждой буквы выделен отдельный стеллаж, поэтому нам не нужно по порядку перебирать все книги, а можно подойти к нужному стеллажу и искать уже там. Давайте рассмотрим пример реализации хеш-таблицы на языке C#.
Существуют два основных способа реализации хеш-таблиц:
- Метод цепочек (открытое хеширование) — все элементы данных с совпадающем хешем объединяются в список.
- Метод открытой адресации (закрытое хеширование) — добавляем элемент данных в ячейку по хешу, если эта ячейка занята, то переходим в следующую до тех пор, пока не найдем свободную.
В данном примере мы будем реализовывать первый вариант.
На рисунке ниже представлена схематичная структура хеш-таблицы.
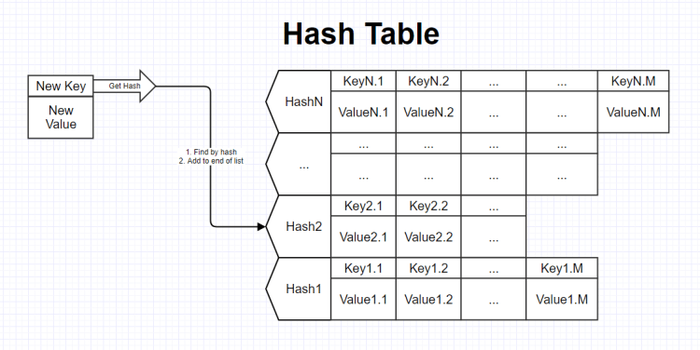
Доступ к элементам осуществляется по его ключу. Основные операции, которые могут выполняться с хеш-таблицей?
- Insert — добавить новый элемент в хеш-таблицу
- Delete — удалить элемент из хеш-таблицы по ключу
- Search — получить значение по ключу
Основной принцип работы хеш-таблицы заключается в том, что в качестве входных параметров она принимает пары ключ-значение. Затем с помощью специальной хеш функции получает короткий ключ на основе полученного ключа. И наконец добавляет данные в таблицу. Если в таблице уже существует значения с таким хешем, то объединяет их в коллекции. Внутри коллекции поиск выполняется по изначальному полученному ключу.
Теперь приступим к реализации данной структуры данных. Для простоты будем рассматривать структуру из пары двух строк. Данная реализация является весьма примитивной, но позволяет разобраться в структуре и алгоритме работы данного типа данных.
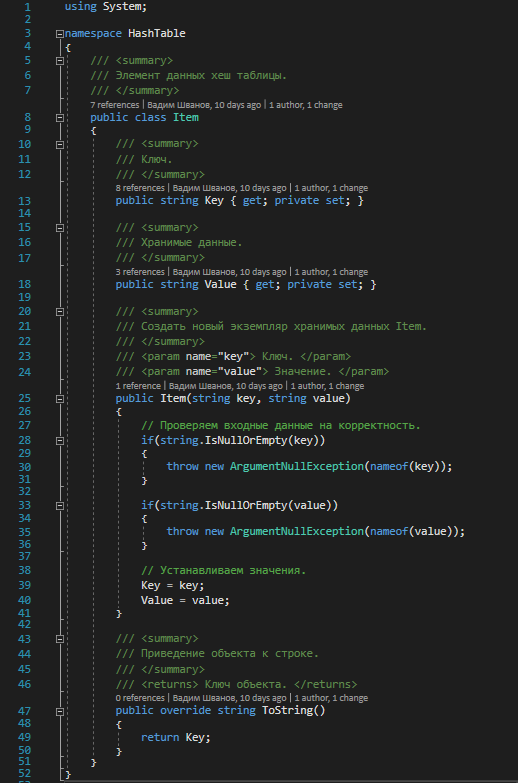
Класс элемента данных хеш-таблицы
Класс хеш-таблицы
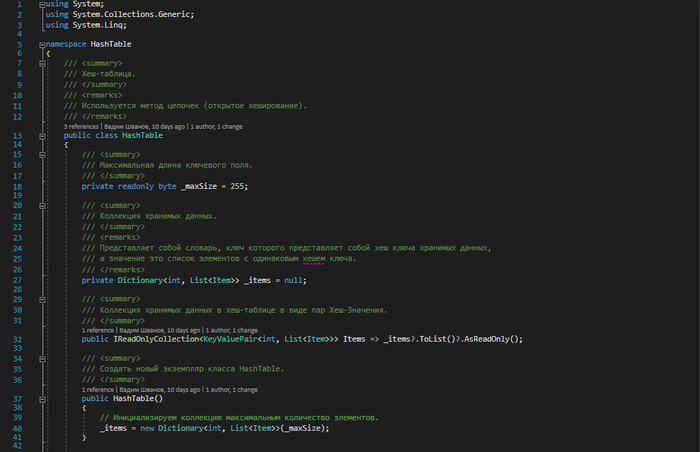
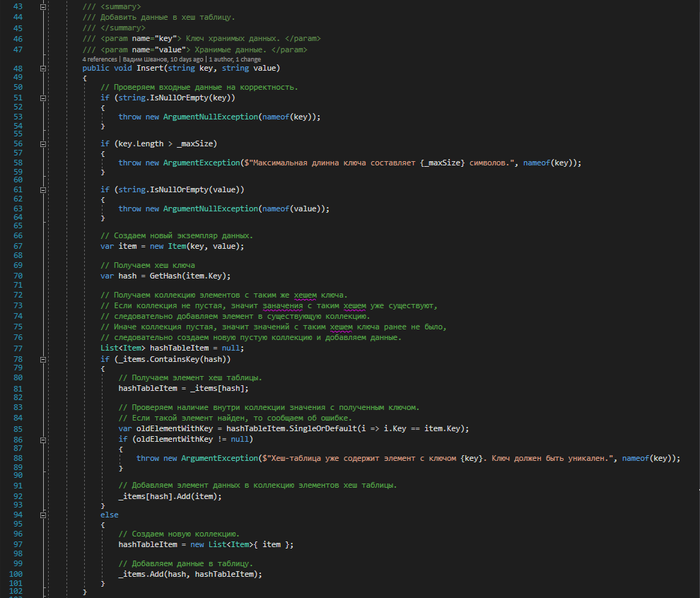
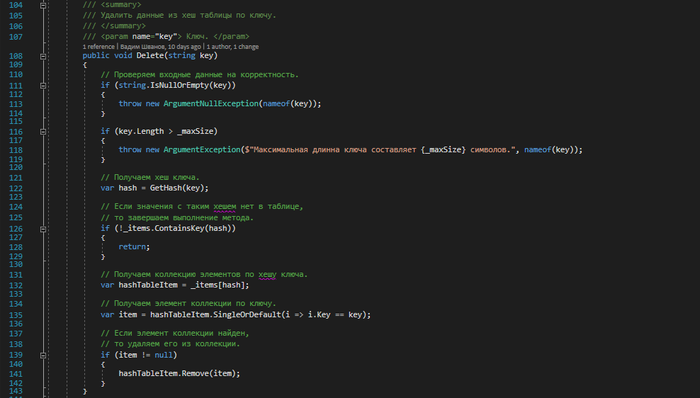
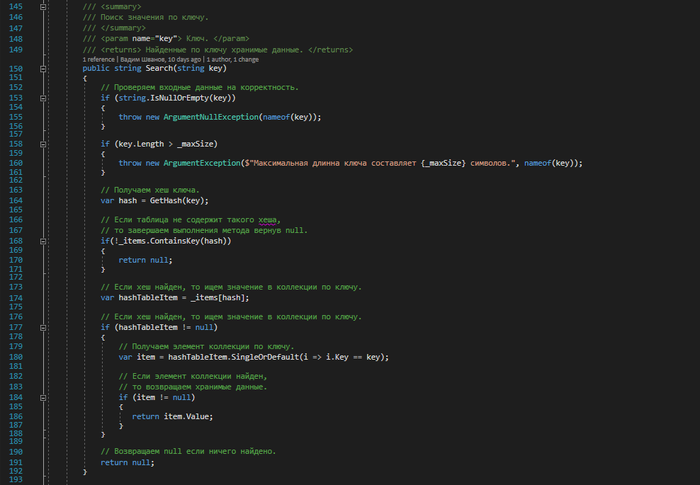
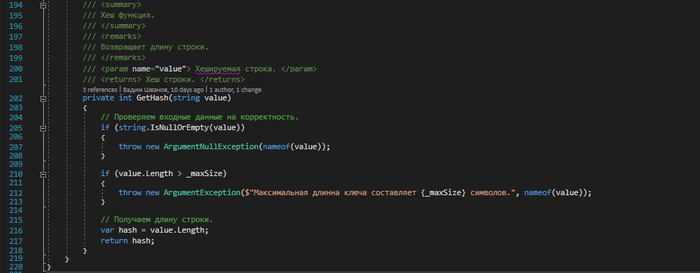
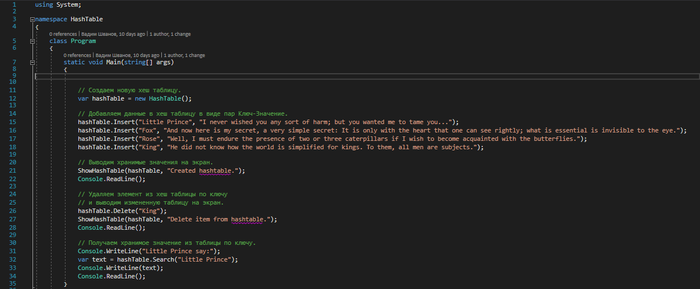
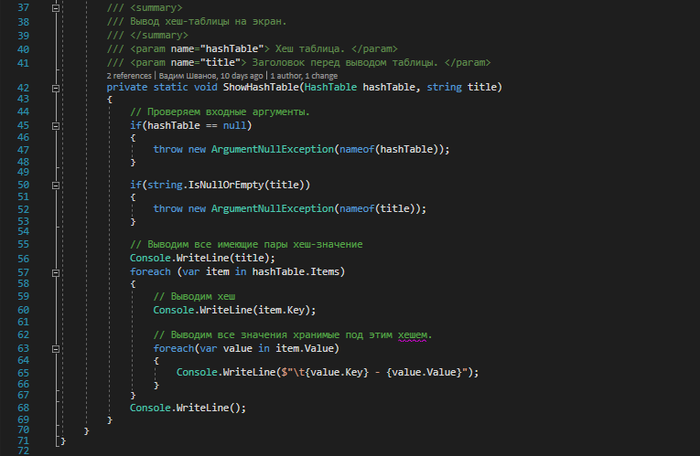
Работа с хеш-таблицей
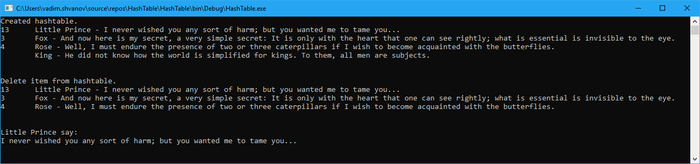
Результат работы приложения
На платформе .NET уже есть готовая реализация данной структуры данных. Она содержится в пространстве имен System.Collections и называется аналогично Hashtable. Я не претендую на правильность, оптимальность и красоту реализации. Единственная цель, которую я преследую, поделиться полезной информацией о программировании, которая может кому-то пригодиться.
Источник: https://shwan.ru/hashtable/

Словарь (map) — это структура данных, представляющая собой специальным образом организованный набор элементов хранимых данные. Все данные хранятся в виде пар ключ-значение. Доступ к элементам данных осуществляется по ключу. Ключ всегда должен быть уникальным в пределах одного словаря, данные могут дублироваться при необходимости. У данной структуры есть и другие часто встречающиеся названия: ассоциативный массив или Dictionary. Принцип работы словаря схож с камерой хранения: есть ячейка, в которой может храниться что угодно, но доступ к этой ячейке осуществляется по уникальному номеру, благодаря чему ее всегда легко найти. Давайте рассмотрим пример реализации словаря на языке C#.
На рисунке ниже представлена схематичная структура словаря.
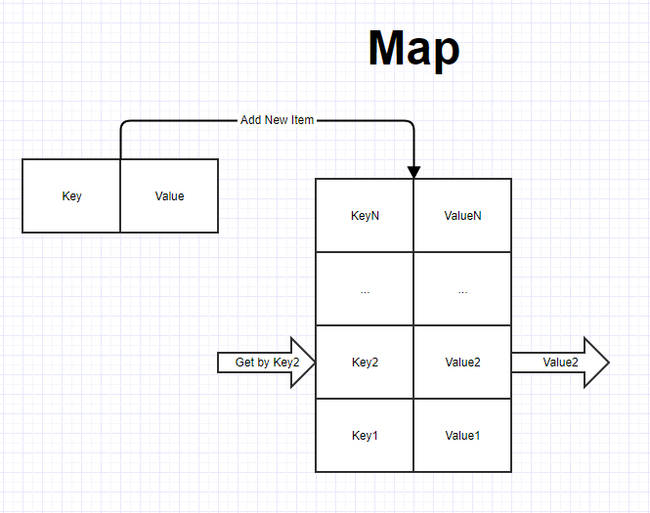
У словаря доступ осуществляется к любому из элементов хранимых данные по его ключу. Основные операции, которые могут выполняться со словарем:
1. Add — добавление нового элемента с уникальным ключом.
2. Remove — удаление элемента по ключу.
3. Update — изменить хранимое значение по ключу.
4. Get — получить хранимое значение по ключу.
Теперь приступим к реализации данной структуры данных. Будем использовать обобщенный класс с двумя принимаемыми типами для ключа и значения. Для хранения данных воспользуемся списком. Данная реализация является весьма примитивной, но позволяет разобраться в структуре и алгоритме работы данного типа данных.
Теперь рассмотрим программный код.
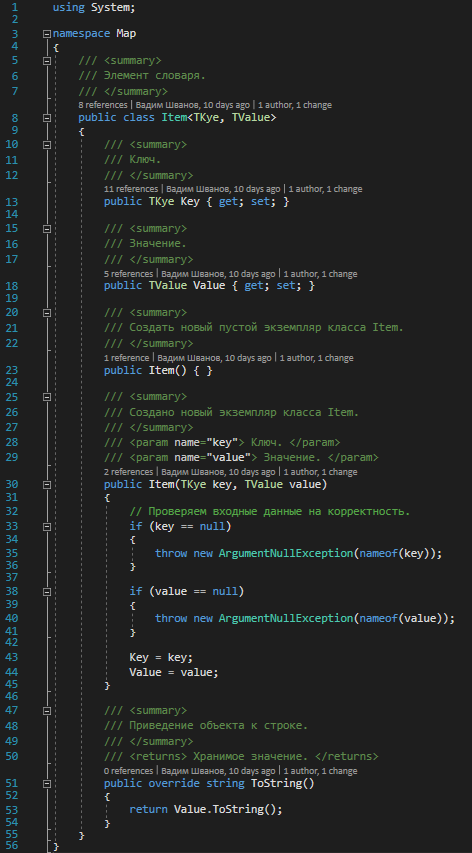
Элемент словаря
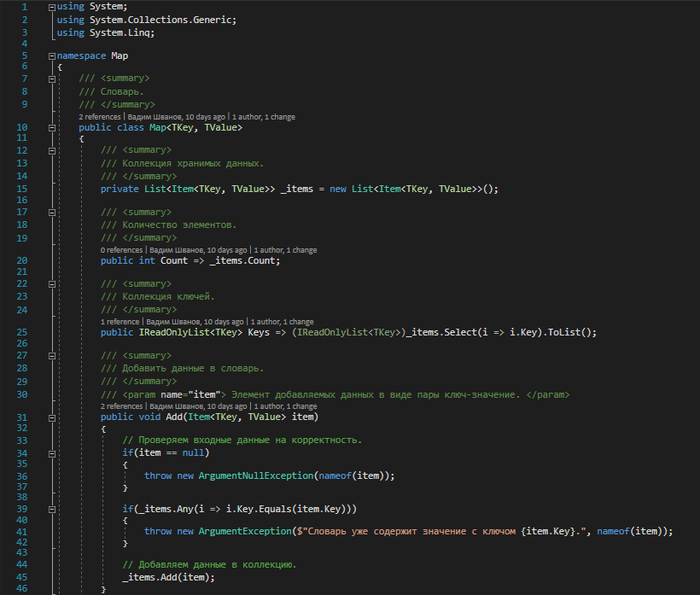
Объявим класс словаря, его свойства и реализуем основные операции


Теперь проверим работу словаря обратившись к нему
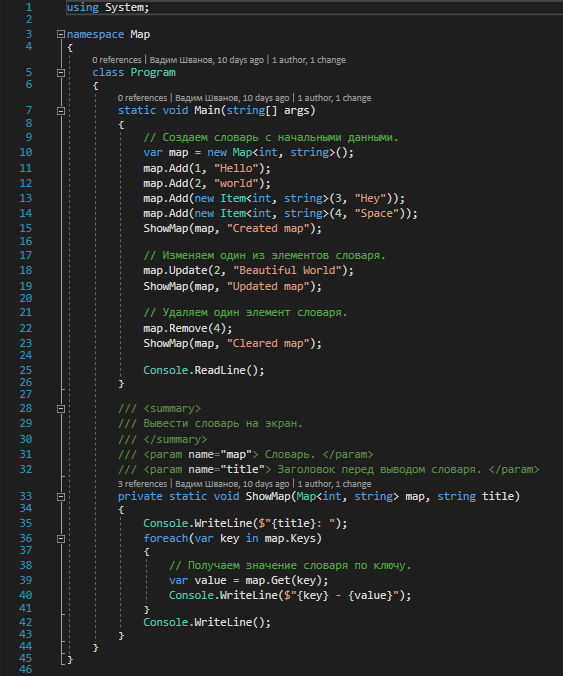
Ну и наконец запустим приложение и посмотрим результат работы на консоли
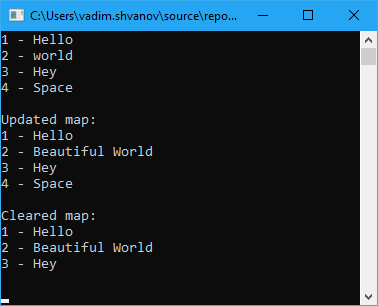
Заключение
На платформе .NET уже есть готовая реализация данной структуры данных. Она содержится в пространстве имен System.Collections и называется Dictionary. Я не претендую на правильность, оптимальность и красоту реализации. Единственная цель, которую я преследую, поделиться полезной информацией о программировании, которая может кому-то пригодиться.
Источник: https://shwan.ru/map/
Множество (set) — это структура данных, представляющая собой не организованный набор уникальных элементов одного типа. Данная структура очень тесно связано с математическим понятием теории множеств. В наиболее упрощенном понимании, множество — это набор уникальных однотипных данных, рассматриваемых как единое целое. Давайте рассмотрим пример реализации множества и основных операций выполняемых с множествами на языке C#.
На рисунке ниже схематически представлены два множества A и B, а также основные операции: объединение, пересечение, разность.
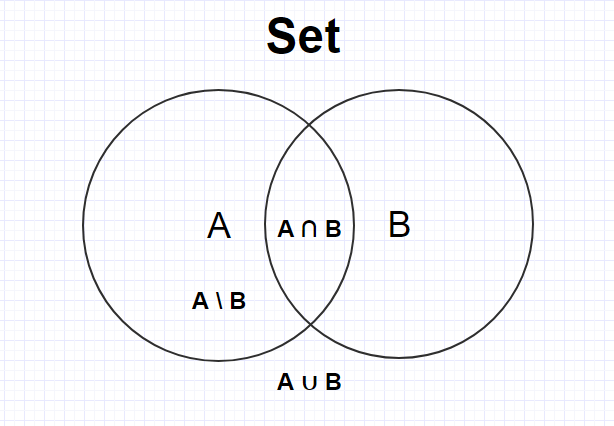
Давайте подробнее рассмотрим все наиболее часто встречающиеся операции над множествами:
1. Add — добавление элемента. Если такой элемент уже присутствует, то он не будет добавлен.
Remove — удаление элемента из множества.
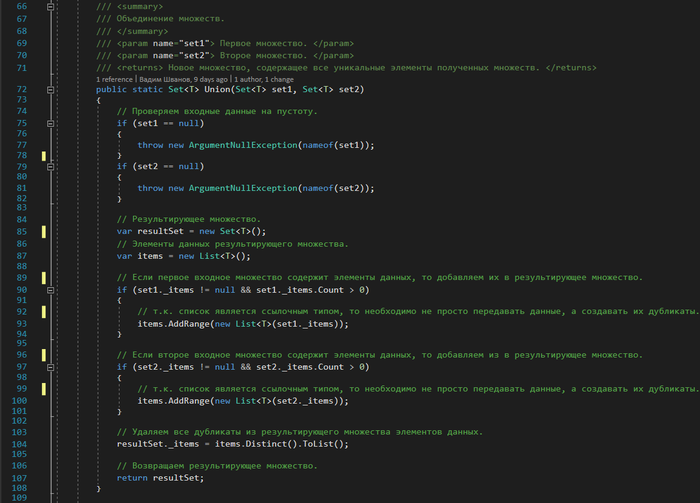
2. Union — объединение множеств. Создается новое множество, включающее в себя все элементы из множества А и множества В. Если элемент содержится в обоих множествах, он будет добавлен однократно.
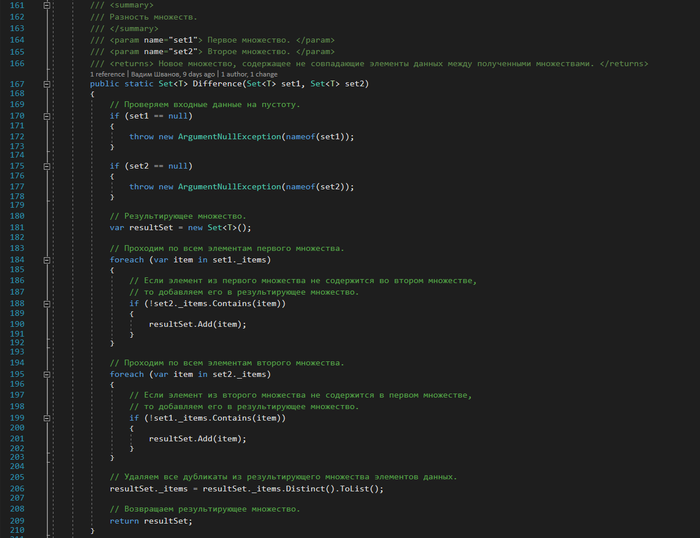
3. Difference — разность множеств. Создается новое множество, включающее в себя все элементы множества А, которые не входят в множество В.
4. Intersection — пересечение множеств. Создается новое множество, включающее в себя все элементы входящие одновременно и в множество А, и в множество В.
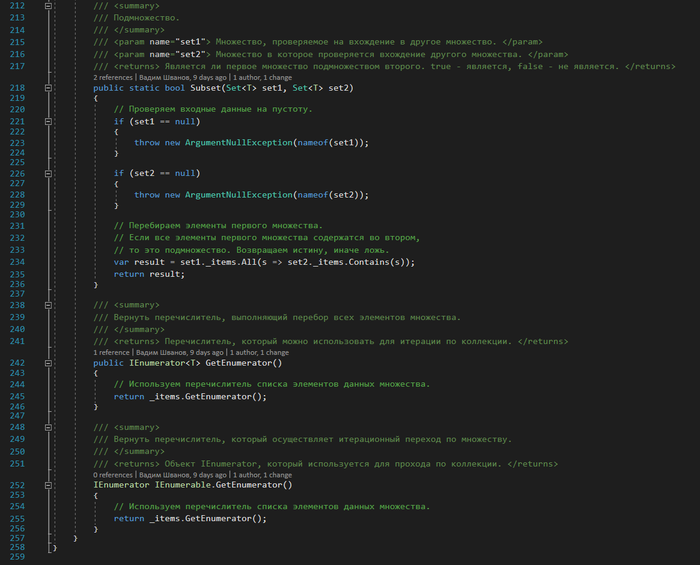
5.Subset — проверка на подмножество. Чтобы быть подмножеством, все элементы множества А должны содержаться в множестве В. Тогда множество А является подмножеством множества В.
Теперь приступим к реализации данного класса. Будем использовать обобщенный класс и реализовывать интерфейс IEnumerable для произвольного доступа к элементам множества. Для хранения данных воспользуемся списком. Данная реализация является весьма примитивной и не оптимальной, но возможность разобраться в алгоритмах работы основных операций над множествами.
Реализация класса Set.cs
Для начала объявим класс и его свойства
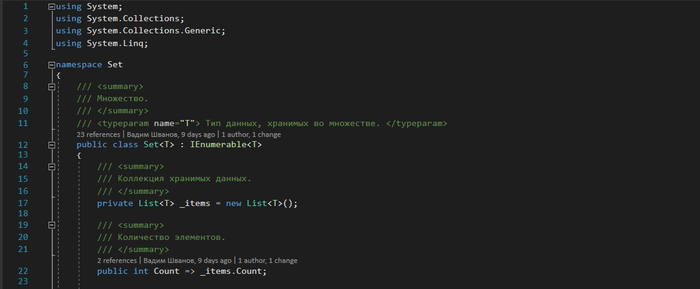
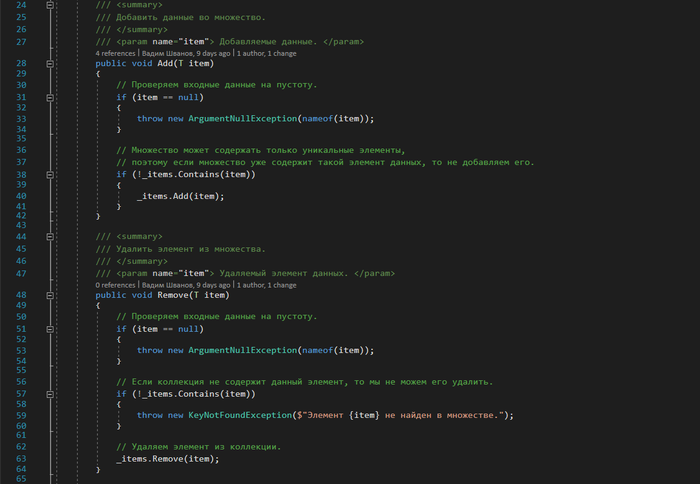
Теперь реализуем операции добавления и удаления элементов множества
Теперь реализуем операцию объединения множеств
Реализуем операцию пересечения множеств

Реализуем операцию разности множеств
Ну и наконец сделаем проверку на подмножество и реализуем интерфейс IEnumerable
Теперь проверим работу нашего класса
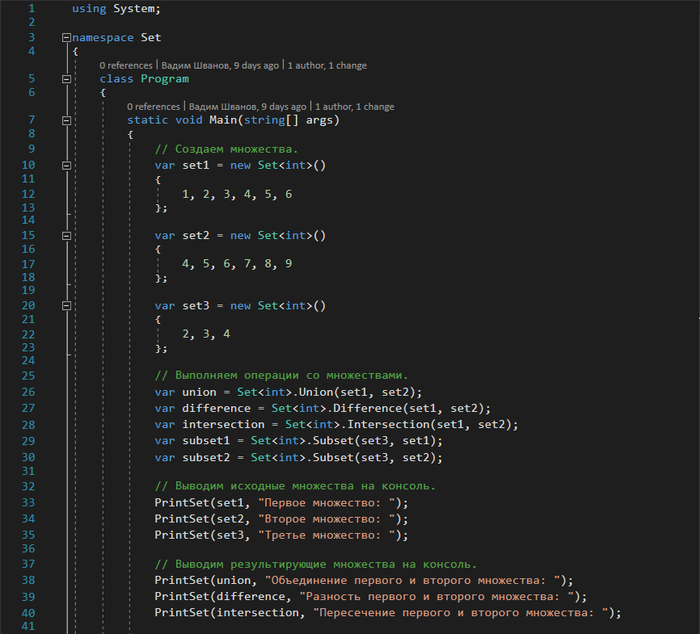
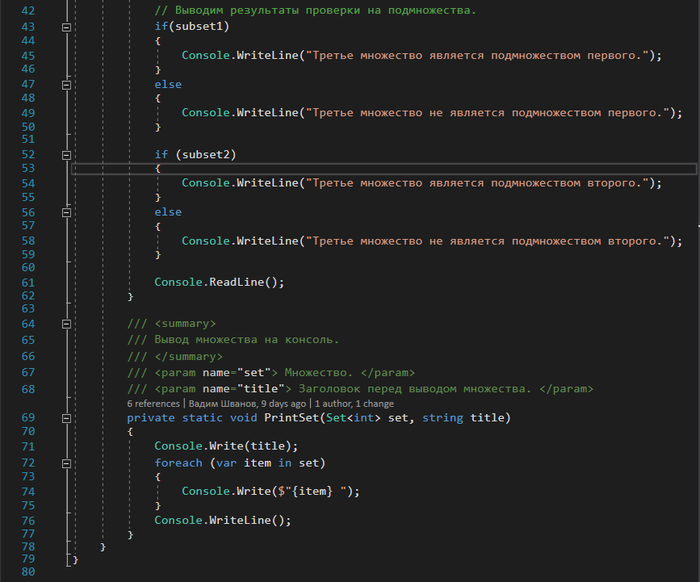
В результате получаем следующий вывод на экран
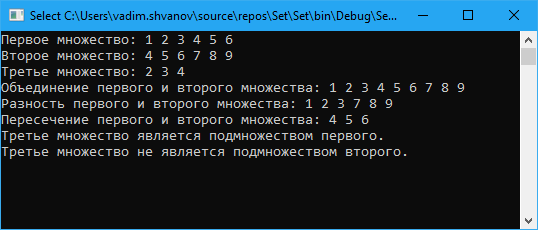
Заключение
На платформе .NET все операции над множествами уже оптимально реализованы в рамках LINQ запросов, поэтому реализовывать самостоятельно нет необходимости. Я не претендую на правильность, оптимальность и красоту реализации. Единственная цель, которую я преследую, поделиться полезной информацией о программировании, которая может кому-то пригодиться.
Источник https://shwan.ru/set/






